file: ./content/docs/index.en.mdx
meta: {
"title": "Quick Start",
"description": "Access hundreds of AI models via OhMyGPT's unified API.",
"icon": "Rocket"
}
You can access hundreds of AI models through OhMyGPT's unified API. Learn how to integrate using the OpenAI SDK, direct API calls, or third-party frameworks.
OhMyGPT provides a unified API that lets you access hundreds of AI models through a single endpoint. It automatically handles fallback options and selects the most cost-effective model. With just a few lines of code, you can get started using your preferred SDK or framework.
Want to chat with our docs? Download our [LLM-friendly text file](/llms.txt) and include it in your system prompt.
## Using the OpenAI SDK
```python tab="Python"
from openai import OpenAI
client = OpenAI(
base_url="https://api.ohmygpt.com/v1",
api_key="",
)
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": "What is the meaning of life?"
}
]
)
print(completion.choices[0].message.content)
```
```typescript tab="TypeScript"
import OpenAI from 'openai';
const openai = new OpenAI({
baseURL: 'https://api.ohmygpt.com/v1',
apiKey: '',
});
async function main() {
const completion = await openai.chat.completions.create({
model: 'gpt-4o',
messages: [{
role: 'user',
content: 'What is the meaning of life?',
},
],
});
console.log(completion.choices[0].message);
}
main();
```
file: ./content/docs/index.mdx
meta: {
"title": "快速开始",
"description": "通过OhMyGPT的统一API访问数百种AI模型。",
"icon": "Rocket"
}
您可以通过OhMyGPT的统一API访问数百种AI模型。了解如何使用OpenAI SDK、直接API调用或第三方框架进行集成。
OhMyGPT提供了一个统一的API,通过单一端点让您访问数百种AI模型,同时自动处理后备选项并选择最具成本效益的选择。只需几行代码,就可以从您喜欢的SDK或框架开始。
想要与我们的文档聊天?下载我们的[LLM友好文本文件](/llms.txt),并将其包含在您的系统提示中。
## 使用OpenAI SDK
```python tab="Python"
from openai import OpenAI
client = OpenAI(
base_url="https://api.ohmygpt.com/v1",
api_key="",
)
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": "生命的意义是什么?"
}
]
)
print(completion.choices[0].message.content)
```
```typescript tab="TypeScript"
import OpenAI from 'openai';
const openai = new OpenAI({
baseURL: 'https://api.ohmygpt.com/v1',
apiKey: '',
});
async function main() {
const completion = await openai.chat.completions.create({
model: 'gpt-4o',
messages: [{
role: 'user',
content: '生命的意义是什么?',
},
],
});
console.log(completion.choices[0].message);
}
main();
```
file: ./content/docs/api-reference/authentication.en.mdx
meta: {
"title": "Authentication",
"description": "API Authentication",
"icon": "UserLock"
}
You must protect your API keys and never commit them to public code repositories.
It is highly recommended to use environment variables and keep your keys out of your codebase.
# Authentication
Our API uses Bearer tokens for authentication. This allows you to interact with OhMyGPT directly using `curl` or the [OpenAI SDK](https://platform.openai.com/docs/frameworks).
## Using API Keys
To use an API key, first [create your key](https://next.ohmygpt.com/apis/keys). Give it a name, and you can optionally set a credit limit.
If you are calling the OhMyGPT API directly, set the `Authorization` header to a Bearer token with your API key.
If you are using the OpenAI Typescript SDK, set `api_base` to [https://api.ohmygpt.com](https://api.ohmygpt.com) and `apiKey` to your API key.
```typescript tab="TypeScript (Bearer Token)"
fetch('https://api.ohmygpt.com/v1/chat/completions', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gpt-4o',
messages: [
{
role: 'user',
content: 'What is the meaning of life?',
},
],
}),
});
```
```typescript tab="TypeScript (OpenAI SDK)"
import OpenAI from 'openai';
const openai = new OpenAI({
baseURL: 'https://api.ohmygpt.com/v1',
apiKey: '',
});
async function main() {
const completion = await openai.chat.completions.create({
model: 'gpt-4o',
messages: [{ role: 'user', content: 'Say this is a test' }],
});
console.log(completion.choices[0].message);
}
main();
```
```python tab="Python"
import openai
openai.api_base = "https://api.ohmygpt.com/v1"
openai.api_key = ""
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[...],
)
reply = response.choices[0].message
```
file: ./content/docs/api-reference/authentication.mdx
meta: {
"title": "认证",
"description": "API 认证",
"icon": "UserLock"
}
您必须保护您的API密钥,切勿将其提交到公共代码库中。
强烈建议使用环境变量并将密钥保留在代码库之外。
# 认证
我们的 API 使用 Bearer 令牌进行身份验证。这允许您直接使用 `curl` 或 [OpenAI SDK](https://platform.openai.com/docs/frameworks) 与 OhMyGPT 进行交互。
## 使用 API 密钥
要使用 API 密钥,首先[创建您的密钥](https://next.ohmygpt.com/apis/keys)。给它一个名称,您可以选择性地设置信用额度。
如果您直接调用 OhMyGPT API,请将 `Authorization` 头设置为带有您的 API 密钥的 Bearer 令牌。
如果您使用 OpenAI Typescript SDK,请将 `api_base` 设置为 [https://api.ohmygpt.com](https://api.ohmygpt.com) ,并将 `apiKey` 设置为您的 API 密钥。
```typescript tab="TypeScript (Bearer Token)"
fetch('https://api.ohmygpt.com/v1/chat/completions', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gpt-4o',
messages: [
{
role: 'user',
content: 'What is the meaning of life?',
},
],
}),
});
```
```typescript tab="TypeScript (OpenAI SDK)"
import OpenAI from 'openai';
const openai = new OpenAI({
baseURL: 'https://api.ohmygpt.com.ai/v1',
apiKey: '',
});
async function main() {
const completion = await openai.chat.completions.create({
model: 'gpt-4o',
messages: [{ role: 'user', content: 'Say this is a test' }],
});
console.log(completion.choices[0].message);
}
main();
```
```python tab="Python"
import openai
openai.api_base = "https://api.ohmygpt.com/v1"
openai.api_key = ""
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[...],
)
reply = response.choices[0].message
```
file: ./content/docs/api-reference/errors.en.mdx
meta: {
"title": "Errors",
"description": "API Errors",
"icon": "CircleAlert"
}
## Error Codes
* 400: Bad Request (invalid or missing parameters, cross-origin resource sharing issues)
* 401: Invalid Credentials (OAuth session expired, disabled/invalid API key)
* 402: Your account or API key has insufficient balance. Please recharge and retry the request.
* 403: The model you selected requires moderation, and your input has been flagged
* 408: Your request timed out
* 429: You are rate limited
* 502: The model you selected is unavailable or we received an invalid response from it
* 503: No available model providers to fulfill your routing requirements
file: ./content/docs/api-reference/errors.mdx
meta: {
"title": "错误",
"description": "API 错误",
"icon": "CircleAlert"
}
## 错误代码
* 400:错误请求(无效或缺少参数,跨源资源共享问题)
* 401:无效凭证(OAuth 会话过期,禁用/无效的 API 密钥)
* 402:您的账户或 API 密钥余额不足。请充值并重新尝试请求。
* 403:您选择的模型需要审核,您的输入已被标记
* 408:您的请求超时
* 429:您被限制了访问速率
* 502:您选择的模型不可用或我们从其收到无效响应
* 503:没有满足您的路由要求的可用模型提供商
file: ./content/docs/api-reference/limits.en.mdx
meta: {
"title": "Limits",
"description": "Rate Limits",
"icon": "CircleGauge"
}
To ensure fair allocation of API quotas, we assign different rate limits based on the user's cumulative recharge record:
| Membership Level | Cumulative Recharge | API Limit (requests/minute) | Core Advantages/Suitable Users |
| :--------------- | :------------------ | :-------------------------- | :------------------------------------------------------------ |
| Free | ¥0+ | 60 | Free trial, basic functionality, users trying out the service |
| VIP | ¥20+ | 1200 | Increased API rate, suitable for individuals/small teams |
| Premium | ¥300+ | 10000 | High API rate, priority support, high demand/enterprise users |
The system automatically assigns the corresponding level and rate limit based on your recharge history.
file: ./content/docs/api-reference/limits.mdx
meta: {
"title": "限制",
"description": "速率限制",
"icon": "CircleGauge"
}
为了确保API配额的公平分配,我们根据用户的累计充值记录分配不同的速率限制:
| 会员等级 | 累计充值 | API 限制 (次/分钟) | 核心优势/适合用户 |
| :------ | :---- | :------------ | :--------------------- |
| Free | ¥0+ | 60 | 免费体验,基础功能,尝鲜用户 |
| VIP | ¥20+ | 1200 | 提升API速率,适用于个人/小型团队 |
| Premium | ¥300+ | 10000 | 高速率API,提供优先支持,高需求/企业用户 |
系统会根据您的充值记录自动给您分配对应的等级和速率限制。
file: ./content/docs/api-reference/overview.en.mdx
meta: {
"title": "Overview",
"description": "OhMyGPT API Overview",
"icon": "BookOpen"
}
OhMyGPT's request and response patterns are very similar to the OpenAI Chat API, with only minor differences. Overall, **OhMyGPT standardizes the schema across different models and providers**, so you only need to learn one way to use it.
file: ./content/docs/api-reference/overview.mdx
meta: {
"title": "概述",
"description": "OhMyGPT API 概述",
"icon": "BookOpen"
}
OhMyGPT 的请求和响应模式与 OpenAI Chat API 非常相似,只有一些小的差异。总体上,**OhMyGPT 在不同模型和提供商之间标准化了模式**,这样您只需要学习一种使用方式。
file: ./content/docs/api-reference/parameters.en.mdx
meta: {
"title": "Parameters",
"description": "API Parameters",
"icon": "SlidersHorizontal"
}
Sampling parameters determine the model's token generation process. You can send any of the parameters from the following list, as well as other parameters, to OhMyGPT.
If some parameters are missing in the request, OhMyGPT will default to the values listed below (e.g., `temperature` defaults to 1.0). We will also pass some provider-specific parameters directly to the corresponding provider, such as Mistral's `safe_prompt` or Hyperbolic's `raw_mode` (if specified).
Please refer to the model provider section to confirm which parameters are supported.
## Temperature
* Parameter Name: `temperature`
* Optional, `float`
* Range: `0.0` - `2.0`
* Default Value: `1.0`
This setting affects the diversity of the model's responses. Lower values lead to more predictable and typical responses, while higher values encourage more diverse and less common responses. When set to 0, the model always gives the same response for a given input.
## Top P
* Parameter Name: `top_p`
* Optional, `float`
* Range: `0.0` - `1.0`
* Default Value: `1.0`
This setting limits the model's choices to the top tokens whose probability sum reaches P. Lower values make the model's responses more predictable, while the default setting allows the model to choose from all possible tokens. It can be thought of as dynamic Top-K.
## Top K
* Parameter Name: `top_k`
* Optional, `integer`
* Range: `0` or above
* Default Value: `0`
Limits the scope of the model's token selection at each step, causing it to choose from a smaller set. A value of 1 means the model will always choose the most likely next token, resulting in predictable results. By default, this setting is disabled, allowing the model to consider all choices.
## Frequency Penalty
* Parameter Name: `frequency_penalty`
* Optional, `float`
* Range: `-2.0` - `2.0`
* Default Value: `0.0`
This setting is designed to control token repetition, based on their frequency in the input. It attempts to reduce the use of tokens that appear more frequently in the input, in proportion to their frequency of appearance. Token penalty increases with the number of occurrences. Negative values encourage token reuse.
## Presence Penalty
* Parameter Name: `presence_penalty`
* Optional, `float`
* Range: `-2.0` - `2.0`
* Default Value: `0.0`
Adjusts the frequency with which the model repeats specific tokens already used in the input. Higher values make this repetition less likely, while negative values do the opposite. The token penalty does not increase with the number of occurrences. Negative values encourage token reuse.
## Repetition Penalty
* Parameter Name: `repetition_penalty`
* Optional, `float`
* Range: `0.0` - `2.0`
* Default Value: `1.0`
Helps reduce repeating tokens from the input. Higher values make the model less likely to repeat tokens, but excessively high values may make the output less coherent (often resulting in continuous sentences with missing small words). The token penalty is calculated based on the probability of the original token.
## Min P
* Parameter Name: `min_p`
* Optional, `float`
* Range: `0.0` - `1.0`
* Default Value: `0.0`
Represents the minimum probability for a token to be considered, relative to the probability of the most likely token. (The value varies depending on the confidence level of the most likely token). If your Min-P is set to 0.1, this means that it will only allow tokens that are at least 1/10th as likely as the best possible option.
## Top A
* Parameter Name: `top_a`
* Optional, `float`
* Range: `0.0` - `1.0`
* Default Value: `0.0`
Only consider the top tokens with "high enough" probability based on the probability of the most likely token. Think of it as dynamic Top-P. Lower Top-A values focus selection based on the highest probability token but with a narrower range. Higher Top-A values do not necessarily influence the creativity of the output, but optimize the filtering process based on maximum probability.
## Seed
* Parameter Name: `seed`
* Optional, `integer`
If specified, inference will sample deterministically, such that repeated requests with the same seed and parameters should return the same results. Some models do not guarantee determinism.
## Max Tokens
* Parameter Name: `max_tokens`
* Optional, `integer`
* Range: `1` or above
Sets the upper limit on the number of tokens the model can generate in the response. It will not generate content beyond this limit. The maximum value is the context length minus the prompt length.
## Logit Bias
* Parameter Name: `logit_bias`
* Optional, `map`
Accepts a JSON object that maps tokens (specified by their token ID in the tokenizer) to an associated bias value from -100 to 100. Mathematically, the bias is added to the logits generated by the model before sampling. The exact effect varies per model, but values between -1 and 1 should decrease or increase likelihood of selection; values like -100 or 100 should result in near forbidden or exclusive selection of the relevant token.
## Logprobs
* Parameter Name: `logprobs`
* Optional, `boolean`
Whether to return log probabilities of the output tokens. If true, returns the log probabilities of each output token.
## Top Logprobs
* Parameter Name: `top_logprobs`
* Optional, `integer`
* Range: `0` - `20`
Specifies the number of most likely tokens to return at each token position, each with an associated log probability. logprobs must be set to true if using this parameter.
## Response Format
* Parameter Name: `response_format`
* Optional, `map`
Forces the model to generate a specific output format. Set to `{ "type": "json_object" }` to enable JSON mode, which guarantees that the model-generated message is valid JSON.
**Note**: When using JSON mode, you should also instruct the model to generate JSON yourself via system or user messages.
## Structured Outputs
* Parameter Name: `structured_outputs`
* Optional, `boolean`
Whether the model can return structured outputs using response\_format json\_schema.
## Stop
* Parameter Name: `stop`
* Optional, `array`
If the model encounters any tokens specified in the stop array, it immediately stops generating.
## Tools
* Parameter Name: `tools`
* Optional, `array`
The tool calling parameter, which follows the OpenAI's tool calling request format. It will be converted accordingly for non-OpenAI providers.
## Tool Choice
* Parameter Name: `tool_choice`
* Optional, `array`
Controls which (if any) tool is called by the model. 'none' means the model will not call any tool and instead generate a message. 'auto' means the model can pick between generating a message or calling one or more tools. 'required' means the model must call one or more tools. Specifying a particular tool via `{"type": "function", "function": {"name": "my_function"}}` forces the model to call that tool.
file: ./content/docs/api-reference/parameters.mdx
meta: {
"title": "参数",
"description": "API 参数",
"icon": "SlidersHorizontal"
}
采样参数决定了模型的令牌生成过程。您可以向 OhMyGPT 发送以下列表中的任何参数,以及其他参数。
如果请求中缺少某些参数,OhMyGPT 将默认使用下面列出的值(例如,`temperature` 默认为 1.0)。我们还会将一些特定提供商的参数直接传递给相应的提供商,例如 Mistral 的 `safe_prompt` 或 Hyperbolic 的 `raw_mode`(如果指定)。
请参考模型提供商部分,确认支持哪些参数。
## Temperature
* 参数名:`temperature`
* 可选,`float`
* 范围:`0.0` - `2.0`
* 默认值:`1.0`
此设置影响模型响应的多样性。较低的值会导致更可预测和典型的响应,而较高的值会鼓励更多样化且不太常见的响应。当设为0时,模型对于给定输入总是给出相同的响应。
## Top P
* 参数名:`top_p`
* 可选,`float`
* 范围:`0.0` - `1.0`
* 默认值:`1.0`
此设置将模型的选择限制在概率总和达到P的顶部令牌。较低的值使模型的响应更可预测,而默认设置允许模型在所有可能的令牌中进行选择。可以将其视为动态的Top-K。
## Top K
* 参数名:`top_k`
* 可选,`integer`
* 范围:`0`或以上
* 默认值:`0`
限制模型在每一步选择令牌的范围,使其从较小的集合中选择。值为1意味着模型将始终选择最可能的下一个令牌,导致结果可预测。默认情况下,此设置被禁用,允许模型考虑所有选择。
## Frequency Penalty
* 参数名:`frequency_penalty`
* 可选,`float`
* 范围:`-2.0` - `2.0`
* 默认值:`0.0`
此设置旨在控制令牌的重复,基于它们在输入中出现的频率。它尝试减少那些在输入中出现更频繁的令牌的使用,与它们出现的频率成比例。令牌惩罚随出现次数而增加。负值会鼓励令牌重复使用。
## Presence Penalty
* 参数名:`presence_penalty`
* 可选,`float`
* 范围:`-2.0` - `2.0`
* 默认值:`0.0`
调整模型重复输入中已使用的特定令牌的频率。较高的值使这种重复不太可能发生,而负值则相反。令牌惩罚不随出现次数而增加。负值会鼓励令牌重复使用。
## Repetition Penalty
* 参数名:`repetition_penalty`
* 可选,`float`
* 范围:`0.0` - `2.0`
* 默认值:`1.0`
帮助减少从输入中重复令牌。较高的值使模型不太可能重复令牌,但过高的值可能使输出不太连贯(通常会出现缺少小词的连续句子)。令牌惩罚基于原始令牌的概率来计算。
## Min P
* 参数名:`min_p`
* 可选,`float`
* 范围:`0.0` - `1.0`
* 默认值:`0.0`
表示相对于最可能令牌的概率,一个令牌被考虑的最小概率。(该值根据最可能令牌的置信度水平而变化)。如果您的Min-P设置为0.1,这意味着它只允许那些至少是最佳可能选项的1/10概率的令牌。
## Top A
* 参数名:`top_a`
* 可选,`float`
* 范围:`0.0` - `1.0`
* 默认值:`0.0`
仅考虑基于最可能令牌的概率具有"足够高"概率的顶部令牌。将其视为动态Top-P。较低的Top-A值基于最高概率令牌但范围更窄地集中选择。较高的Top-A值不一定影响输出的创造性,而是基于最大概率优化过滤过程。
## Seed
* 参数名:`seed`
* 可选,`integer`
如果指定,推理将确定性地进行采样,使得具有相同种子和参数的重复请求应返回相同的结果。某些模型不保证确定性。
## Max Tokens
* 参数名:`max_tokens`
* 可选,`integer`
* 范围:`1`或以上
设置模型在响应中可以生成的令牌数量的上限。它不会生成超过此限制的内容。最大值是上下文长度减去提示长度。
## Logit Bias
* 参数名:`logit_bias`
* 可选,`map`
接受一个JSON对象,将令牌(由其在分词器中的令牌ID指定)映射到-100到100之间的相关偏差值。从数学上讲,在采样之前,偏差被添加到模型生成的对数概率中。确切效果因模型而异,但-1到1之间的值应该减少或增加选择的可能性;像-100或100这样的值应该导致禁止或专门选择相关令牌。
## Logprobs
* 参数名:`logprobs`
* 可选,`boolean`
是否返回输出令牌的对数概率。如果为true,则返回每个输出令牌的对数概率。
## Top Logprobs
* 参数名:`top_logprobs`
* 可选,`integer`
* 范围:`0` - `20`
指定在每个令牌位置返回最可能的令牌数量,每个都有相关的对数概率。logprobs必须设置为true如果使用此参数。
## Response Format
* 参数名:`response_format`
* 可选,`map`
强制模型生成特定的输出格式。设置为`{ "type": "json_object" }`启用JSON模式,保证模型生成的消息是有效的JSON。
**注意**:使用JSON模式时,您还应该通过系统或用户消息自己指示模型生成JSON。
## Structured Outputs
* 参数名:`structured_outputs`
* 可选,`boolean`
如果模型可以使用response\_format json\_schema返回结构化输出。
## Stop
* 参数名:`stop`
* 可选,`array`
如果模型遇到stop数组中指定的任何令牌,立即停止生成。
## Tools
* 参数名:`tools`
* 可选,`array`
工具调用参数,遵循OpenAI的工具调用请求形式。对于非OpenAI提供商,它将相应地进行转换。
## Tool Choice
* 参数名:`tool_choice`
* 可选,`array`
控制模型调用哪个(如果有)工具。'none'表示模型不会调用任何工具,而是生成消息。'auto'表示模型可以选择生成消息或调用一个或多个工具。'required'表示模型必须调用一个或多个工具。通过`{"type": "function", "function": {"name": "my_function"}}`指定特定工具会强制模型调用该工具。
file: ./content/docs/api-reference/streaming.en.mdx
meta: {
"title": "Streaming",
"icon": "ChartNoAxesGantt"
}
The OhMyGPT API allows streaming responses from any model. This is very useful for building chat interfaces or other applications where the user interface should be updated as the model generates the response.
To enable streaming, you can set the `stream` parameter to `true` in your request. The model will then stream the response to the client in chunks, rather than returning the entire response at once.
Here's an example of how to stream a response and handle it:
```python tab="Python"
import requests
import json
question = "How would you build the tallest building ever?"
url = "https://api.ohmygpt.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer ",
"Content-Type": "application/json"
}
payload = {
"model": "gpt-4o",
"messages": [{"role": "user", "content": question}],
"stream": True
}
buffer = ""
with requests.post(url, headers=headers, json=payload, stream=True) as r:
for chunk in r.iter_content(chunk_size=1024, decode_unicode=True):
buffer += chunk
while True:
try:
# Find the next complete SSE line
line_end = buffer.find('\n')
if line_end == -1:
break
line = buffer[:line_end].strip()
buffer = buffer[line_end + 1:]
if line.startswith('data: '):
data = line[6:]
if data == '[DONE]':
break
try:
data_obj = json.loads(data)
content = data_obj["choices"][0]["delta"].get("content")
if content:
print(content, end="", flush=True)
except json.JSONDecodeError:
pass
except Exception:
break
```
```typescript tab="TypeScript"
const question = 'How would you build the tallest building ever?';
const response = await fetch('https://api.ohmygpt.com/v1/chat/completions', {
method: 'POST',
headers: {
Authorization: `Bearer `,
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gpt-4o',
messages: [{ role: 'user', content: question }],
stream: true,
}),
});
const reader = response.body?.getReader();
if (!reader) {
throw new Error('Response body is not readable');
}
const decoder = new TextDecoder();
let buffer = '';
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
// Append new chunk to buffer
buffer += decoder.decode(value, { stream: true });
// Process complete lines from buffer
while (true) {
const lineEnd = buffer.indexOf('\n');
if (lineEnd === -1) break;
const line = buffer.slice(0, lineEnd).trim();
buffer = buffer.slice(lineEnd + 1);
if (line.startsWith('data: ')) {
const data = line.slice(6);
if (data === '[DONE]') break;
try {
const parsed = JSON.parse(data);
const content = parsed.choices[0].delta.content;
if (content) {
console.log(content);
}
} catch (e) {
// Ignore invalid JSON
}
}
}
}
} finally {
reader.cancel();
}
```
## Stream Cancellation
Streaming requests can be cancelled by aborting the connection. For supported providers, this will immediately stop model processing and billing.
**Supported:**
* OpenAI, Azure, Anthropic
* Fireworks, Mancer, Recursal
* AnyScale, Lepton, OctoAI
* Novita, DeepInfra, Together
* Cohere, Hyperbolic, Infermatic
* Avian, XAI, Cloudflare
* SFCompute, Nineteen, Liquid
* Friendli, Chutes, DeepSeek
**Not Supported:**
* AWS Bedrock, Groq, Modal
* Google, Google AI Studio, Minimax
* HuggingFace, Replicate, Perplexity
* Mistral, AI21, Featherless
* Lynn, Lambda, Reflection
* SambaNova, Inflection, ZeroOneAI
* AionLabs, Alibaba, Nebius
* Kluster, Targon, InferenceNet
Here's how to implement stream cancellation:
```python tab="Python"
import requests
from threading import Event, Thread
def stream_with_cancellation(prompt: str, cancel_event: Event):
with requests.Session() as session:
response = session.post(
"https://api.ohmygpt.com/v1/chat/completions",
headers={"Authorization": f"Bearer "},
json={"model": "gpt-4o", "messages": [{"role": "user", "content": prompt}], "stream": True},
stream=True
)
try:
for line in response.iter_lines():
if cancel_event.is_set():
response.close()
return
if line:
print(line.decode(), end="", flush=True)
finally:
response.close()
# Example usage:
cancel_event = Event()
stream_thread = Thread(target=lambda: stream_with_cancellation("Write a story", cancel_event))
stream_thread.start()
# To cancel the stream:
cancel_event.set()
```
```typescript tab="TypeScript"
const controller = new AbortController();
try {
const response = await fetch(
'https://api.ohmygpt.com/v1/chat/completions',
{
method: 'POST',
headers: {
Authorization: `Bearer `,
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gpt-4o',
messages: [{ role: 'user', content: 'Write a story' }],
stream: true,
}),
signal: controller.signal,
},
);
// Process the stream...
} catch (error) {
if (error.name === 'AbortError') {
console.log('Stream cancelled');
} else {
throw error;
}
}
// To cancel the stream:
controller.abort();
```
Cancellation only applies to streaming requests with supported providers. For non-streaming requests or unsupported providers, the model will continue processing, and you will be charged for the full response.
file: ./content/docs/api-reference/streaming.mdx
meta: {
"title": "流",
"icon": "ChartNoAxesGantt"
}
OhMyGPT API 允许从任何模型流式响应。这对于构建聊天界面或其他应用程序非常有用,因为用户界面应该在模型生成响应时进行更新。
要启用流式传输,您可以在请求中将 `stream` 参数设置为 `true` 。然后,模型将以块的形式将响应流式传输到客户端,而不是一次性返回整个响应。
下面是如何流式传输响应并处理它的示例:
```python tab="Python"
import requests
import json
question = "How would you build the tallest building ever?"
url = "https://api.ohmygpt.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer ",
"Content-Type": "application/json"
}
payload = {
"model": "gpt-4o",
"messages": [{"role": "user", "content": question}],
"stream": True
}
buffer = ""
with requests.post(url, headers=headers, json=payload, stream=True) as r:
for chunk in r.iter_content(chunk_size=1024, decode_unicode=True):
buffer += chunk
while True:
try:
# Find the next complete SSE line
line_end = buffer.find('\n')
if line_end == -1:
break
line = buffer[:line_end].strip()
buffer = buffer[line_end + 1:]
if line.startswith('data: '):
data = line[6:]
if data == '[DONE]':
break
try:
data_obj = json.loads(data)
content = data_obj["choices"][0]["delta"].get("content")
if content:
print(content, end="", flush=True)
except json.JSONDecodeError:
pass
except Exception:
break
```
```typescript tab="TypeScript"
const question = 'How would you build the tallest building ever?';
const response = await fetch('https://api.ohmygpt.com/v1/chat/completions', {
method: 'POST',
headers: {
Authorization: `Bearer `,
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gpt-4o',
messages: [{ role: 'user', content: question }],
stream: true,
}),
});
const reader = response.body?.getReader();
if (!reader) {
throw new Error('Response body is not readable');
}
const decoder = new TextDecoder();
let buffer = '';
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
// Append new chunk to buffer
buffer += decoder.decode(value, { stream: true });
// Process complete lines from buffer
while (true) {
const lineEnd = buffer.indexOf('\n');
if (lineEnd === -1) break;
const line = buffer.slice(0, lineEnd).trim();
buffer = buffer.slice(lineEnd + 1);
if (line.startsWith('data: ')) {
const data = line.slice(6);
if (data === '[DONE]') break;
try {
const parsed = JSON.parse(data);
const content = parsed.choices[0].delta.content;
if (content) {
console.log(content);
}
} catch (e) {
// Ignore invalid JSON
}
}
}
}
} finally {
reader.cancel();
}
```
## 流取消
通过中止连接可以取消流式请求。对于支持的提供者,这会立即停止模型处理和计费。
**支持:**
* OpenAI, Azure, Anthropic
* Fireworks, Mancer, Recursal
* AnyScale, Lepton, OctoAI
* Novita, DeepInfra, Together
* Cohere, Hyperbolic, Infermatic
* Avian, XAI, Cloudflare
* SFCompute, Nineteen, Liquid
* Friendli, Chutes, DeepSeek
**不支持:**
* AWS Bedrock, Groq, Modal
* Google, Google AI Studio, Minimax
* HuggingFace, Replicate, Perplexity
* Mistral, AI21, Featherless
* Lynn, Lambda, Reflection
* SambaNova, Inflection, ZeroOneAI
* AionLabs, Alibaba, Nebius
* Kluster, Targon, InferenceNet
实现流取消的方法:
```python tab="Python"
import requests
from threading import Event, Thread
def stream_with_cancellation(prompt: str, cancel_event: Event):
with requests.Session() as session:
response = session.post(
"https://api.ohmygpt.com/v1/chat/completions",
headers={"Authorization": f"Bearer "},
json={"model": "gpt-4o", "messages": [{"role": "user", "content": prompt}], "stream": True},
stream=True
)
try:
for line in response.iter_lines():
if cancel_event.is_set():
response.close()
return
if line:
print(line.decode(), end="", flush=True)
finally:
response.close()
# Example usage:
cancel_event = Event()
stream_thread = Thread(target=lambda: stream_with_cancellation("Write a story", cancel_event))
stream_thread.start()
# To cancel the stream:
cancel_event.set()
```
```typescript tab="TypeScript"
const controller = new AbortController();
try {
const response = await fetch(
'https://api.ohmygpt.com/v1/chat/completions',
{
method: 'POST',
headers: {
Authorization: `Bearer `,
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gpt-4o',
messages: [{ role: 'user', content: 'Write a story' }],
stream: true,
}),
signal: controller.signal,
},
);
// Process the stream...
} catch (error) {
if (error.name === 'AbortError') {
console.log('Stream cancelled');
} else {
throw error;
}
}
// To cancel the stream:
controller.abort();
```
取消仅适用于与支持的提供者的流式请求。对于非流式请求或不支持的提供者,模型将继续处理,您将为完整响应付费。
file: ./content/docs/developer/overview.en.mdx
meta: {
"title": "Overview",
"description": "Developer Overview",
"icon": "BookOpen"
}
Open Authorization (OAuth) is an open standard that allows users to grant third-party applications access to private resources (such as photos, videos, contact lists) stored on a website, without providing the third-party application with their username and password.
***
This site now provides an open OAuth API interface, making it easy for interested developers to integrate their projects into the site, thereby quickly integrating various AI capabilities into your projects without having to worry about user management, API integration, or billing. Focus on function development and implementation, and also have the opportunity to receive rewards, income, and revenue sharing.
Currently, by accessing the API of this site, you can achieve:
* Access the user's UID and email to verify the user's identity
* Query the user's account balance
* Access various APIs on behalf of the user through authorization tokens, such as OpenAI, Anthropic, and other API services
* Get some revenue sharing into your developer account when calling some APIs or services, and can apply for withdrawal
* Actively deduct tokens from the user's account and transfer them to your developer account, and can apply for withdrawal
* Create recharge orders for users to facilitate users to recharge their accounts
Some OAuth App permissions and creation incentives require application and passing developer verification before they can be used.
## Introduction to OAuth Authorization Process
1. Create an OAuth App and obtain the Client ID and Client Secret of this App
2. Read the `User Authorization Page` API documentation, assemble the URL, and have the user open this link for authorization
3. After the user authorizes, the user side will obtain a Code and jump to the redirect URL you set. At this time, you can choose any of the following implementation methods to obtain the Code:
* a. Implement the corresponding Get interface to obtain the Code
* b. Jump to the Code display page and let the user manually copy and paste the Code into your App
4. After obtaining the Code, you can use your `Client ID` + `Client Secret` + `Code` to obtain the OAuth Token of this user through the "Request access\_token" interface
5. After obtaining the OAuth Token, you can use this OAuth Token to access various APIs. Please use it reasonably and keep the Token safe.
## About Developer Verification
In order to ensure user security and compliant operation, we need to verify your identity before allowing you to create OAuth Apps with `trusted_advanced_access` permissions, open a developer income account, and apply for withdrawals.
Please apply for a verified developer account through the customer service email ([help@ohmygpt.com](mailto:help@ohmygpt.com)) or TG administrator. You may need to introduce the project you are currently developing or want to access the advanced OAuth API, your GitHub account, and the payment method for remuneration.
## Developer Permission Levels
| Permission Level | Permission Description |
| -------------------- | ------------------------------------------------------------------------------------------------------------------------------ |
| Basic Permissions | Suitable for basic function access, can only read basic user information |
| General Permissions | Suitable for most application scenarios, can call basic AI APIs on behalf of the user, and read the user's balance information |
| Advanced Permissions | Suitable for scenarios that require operating user data, and can perform paid operations on behalf of the user |
| Full Permissions | Get full access to the user's account, including key management |
### Features Included
**Basic Permissions**
* **Read basic user information**
**General Permissions**
* Basic Permissions
* **Call regular AI APIs**
* **Read user balance information**
**Advanced Permissions**
* General Permissions
* **Charge user fees**
**Full Permissions**
* Advanced Permissions
* **Read user keys**
file: ./content/docs/developer/overview.mdx
meta: {
"title": "概述",
"description": "开发者概述",
"icon": "BookOpen"
}
开放授权(OAuth)是一个开放标准,允许用户让第三方应用访问该用户在某一网站上存储的私密的资源(如照片,视频,联系人列表),而无需将用户名和密码提供给第三方应用。
***
本站现已提供一套开放的OAuth API接口,方便感兴趣的开发者将自己的项目接入到网站上,从而快速地将各种AI能力接入到您的项目的同时,无需关注如用户管理、API整合以及计费等杂项,专注于功能的开发和实现,同时也有机会获取奖励、收益以及分成。
目前,您可以通过接入本站的API实现:
* 访问用户的UID和邮箱,验证用户身份
* 查询用户的账户余额
* 通过授权令牌代表用户访问各种API,如OpenAI、Anthropic等API服务
* 调用部分API或服务时可获得一些分成到您的开发者账户中,可申请提现
* 主动扣除用户账户中的代币,并将其转移到您的开发者账户中,可申请提现
* 为用户创建充值订单,方便用户充值自己的账户
部分OAuth App权限以及创作激励需要申请并通过开发者验证后才能使用
## OAuth 授权流程简介
1. 创建一个 OAuth App,获得此 App 的 Client ID 和 Client Secret
2. 阅读 `用户授权页` API 文档,拼接 URL 并让用户打开此链接进行授权
3. 用户授权后,用户侧会获得一个 Code,并跳转到您设定的重定向 URL 中,此时您可以选择以下任意一种实现方式获得 Code:
* a. 实现相应的 Get 接口,获得 Code
* b. 跳转到 Code 展示页面,让用户手动复制粘贴 Code 到您的 App 中
4. 拿到 Code 后,您可以使用您的 `Client ID` + `Client Secret` + `Code` 通过 “申请access\_token” 接口获得此用户的 OAuth Token
5. 拿到 OAuth Token 后您可以使用此 OAuth Token 访问各种 API,请合理使用并妥善保管 Token
## 关于开发者认证
为了确保用户的安全以及合规运营,我们需要验证您的身份才能允许您创建具有 `trusted_advanced_access` 权限的 OAuth App、开通开发者收益账户以及申请提现等功能
请通过客服邮箱([help@ohmygpt.com](mailto:help@ohmygpt.com))或TG管理员申请开通已验证的开发者账户,您可能需要介绍一下您目前正在开发或想接入高级 OAuth API 的项目、您的 GitHub 账号以及报酬支付方式等。
## 开发者权限级别
| 权限级别 | 权限说明 |
| ---- | -------------------------------------- |
| 基础权限 | 适用于基础功能访问,仅能读取用户的基本信息 |
| 通用权限 | 适用于大多数应用场景,可以代表用户调用基本的AI API,读取用户的余额信息 |
| 高级权限 | 适用于需要操作用户数据的场景,可以代表用户进行付费操作 |
| 完全权限 | 获得用户账户的完整访问权限,包括密钥管理 |
### 包含的功能
**基础权限**
* **读取用户基本信息**
**通用权限**
* 基础权限
* **调用普通AI API**
* **读取用户余额信息**
**高级权限**
* 通用权限
* **收取用户费用**
**完全权限**
* 高级权限
* **读取用户密钥**
file: ./content/docs/files-api/overview.en.mdx
meta: {
"title": "Overview",
"description": "File Storage Service",
"icon": "BookOpen"
}
A file storage service is currently under active development. All users can use about 1GB of storage space for free, and the excess is billed according to standard pricing.
This service plan is a secure, high-speed, cost-effective and controllable file storage service, thus serving as the basic service for file processing related services. For example, providing AI services with functions such as temporary storage of multimodal files/document upload and download, etc. You can also use the storage service of this site to make pictures and beds.
### Pricing
Storage space pricing is as follows:
`$9.9 / TB / Month`
Payments exceeding 1GB free amount will be automatically deducted every hour according to the following standards. The minimum billing unit is 1GB: `3.4375 coin / GB / Hour`
In addition, there is no additional fee, and the request and inbound and outbound traffic fees are exempted.
file: ./content/docs/files-api/overview.mdx
meta: {
"title": "概述",
"description": "文件存储服务",
"icon": "BookOpen"
}
一个文件存储服务,目前正在积极开发中,所有用户均可免费使用约1GB的存储空间,超出的部分按照标准定价计费。
此服务计划作为一个安全、高速、高性价比、可控的文件存储服务,从而作为文件处理相关业务的基础服务,例如为AI服务提供多模态文件临时存储/文档上传下载等功能,您也可以利用本站的存储服务做图床等用途。
### 定价
存储空间定价如下:
`$9.9 / TB / Month`
超出1GB免费额度的付费会每小时按照如下标准自动扣费,最小计费单位为1GB: `3.4375 coin / GB / Hour`
除此之外,无任何额外费用,请求与出入站流量费用全免
file: ./content/docs/features/privacy-and-logging.en.mdx
meta: {
"title": "Privacy and Logging",
"description": "Ensuring Your Data Security",
"icon": "Shield"
}
When using AI through OhMyGPT, whether via the chat interface or API, your prompts and responses pass through multiple touchpoints. You have control over how your data is handled at each stage.
This page aims to provide a practical overview of how your data is processed, stored, and used. For more detailed information, please refer to the Privacy Policy and Terms of Service.
## Within OhMyGPT
OhMyGPT does not store your prompts or responses unless you explicitly enable prompt logging in your account settings. It’s that simple.
OhMyGPT does store metadata about each request (such as the number of prompt and completion tokens, latency, etc.). This supports our reporting, model ranking, and your activity logs.
## Provider Policies
Each provider on OhMyGPT has its own data handling policies.
## Data Retention and Logging
Providers also maintain their own data retention policies, typically for compliance reasons. OhMyGPT does not alter routing rules based on provider data retention policies.
file: ./content/docs/features/privacy-and-logging.mdx
meta: {
"title": "隐私和日志",
"description": "确保您的数据安全",
"icon": "Shield"
}
在通过 OhMyGPT 使用 AI 时,无论是通过聊天界面还是 API,您的提示和响应都会经过多个接触点。您可以控制每个步骤中数据的处理方式。
本页面旨在提供有关您的数据如何处理、存储和使用的实用概述。更多信息请参阅隐私政策和服务条款。
## 在 OhMyGPT 内部
OhMyGPT 不会存储您的提示或响应,除非您在帐户设置中明确选择了提示记录。就是这么简单。
OhMyGPT 会存储每个请求的元数据(例如提示和完成令牌的数量、延迟等)。这用于支持我们的报告和模型排名,以及您的活动记录。
## 提供者政策
OhMyGPT 上的每个提供者都有自己的数据处理政策。
## 数据保留与日志记录
提供者也有自己的数据保留政策,通常出于合规原因。OhMyGPT 没有根据提供者的数据保留政策而改变的路由规则。
file: ./content/docs/features/provisioning-api-keys.en.mdx
meta: {
"title": "Setting Up API Keys",
"description": "Manage API keys programmatically",
"icon": "KeyRound"
}
OhMyGPT provides a series of API interfaces for managing API keys programmatically, supporting application scenarios that require automated key distribution or rotation.
## Creating an Admin API Key
To use the key management API, you first need to create an API key with administrator privileges:
1. Log in to your OhMyGPT account
2. Go to the [API Key Management Page](https://next.ohmygpt.com/apis/keys)
3. Create a new key with administrator privileges
Please note that for security reasons, we do not allow the creation or modification of administrator privileges for other API keys through the API.
## Usage Scenarios
Common scenarios for programmatic key management include:
* **SaaS Applications**: Automatically create unique API keys for each customer instance
* **Key Rotation**: Regularly rotate API keys to comply with security requirements
* **Usage Monitoring**: Track key usage and automatically disable keys that exceed limits
## Example Usage
All key management interfaces require the administrator API key to be included in the request header as a Bearer token.
```python tab="Python"
import requests
# Admin API Key (with management privileges)
ADMIN_API_KEY = "your-admin-api-key"
BASE_URL = "https://api.ohmygpt.com"
# Get all API Keys
response = requests.post(
f"{BASE_URL}/api/v1/user/admin/get-api-tokens",
headers={
"Authorization": f"Bearer {ADMIN_API_KEY}",
"Content-Type": "application/x-www-form-urlencoded"
}
)
```
```typescript tab="TypeScript"
import axios from 'axios';
const ADMIN_API_KEY = 'your-admin-api-key';
const BASE_URL = 'https://api.ohmygpt.com';
// Get all API Keys
const response = await axios.post(
`${BASE_URL}/api/v1/user/admin/get-api-tokens`,
{},
{
headers: {
'Authorization': `Bearer ${ADMIN_API_KEY}`,
'Content-Type': 'application/x-www-form-urlencoded'
}
}
);
```
## Usage Notes
1. **Key Limit**: Each user can create up to 5000 API keys. Exceeding this limit will result in an error.
2. **Administrator Privileges**: For security reasons, creating or modifying administrator privileges for other API keys through the API is not allowed.
3. **Request Limits**:
* Create/Modify/Delete Keys: 10 QPS (Queries Per Second)
* Query All Keys: 1 QPS
4. **Security Recommendations**:
* Rotate API keys regularly
* Use different API keys for different applications or services
* Set appropriate usage limits to prevent abnormal consumption
file: ./content/docs/features/provisioning-api-keys.mdx
meta: {
"title": "设置 API 密钥",
"description": "以编程方式管理 API 密钥",
"icon": "KeyRound"
}
OhMyGPT 提供了一系列管理 API 接口,让您能够以编程方式创建和管理 API 密钥,支持需要自动分发或轮换密钥的应用场景。
## 创建管理员 API 密钥
要使用密钥管理 API,您首先需要创建一个具有管理员权限的 API 密钥:
1. 登录您的 OhMyGPT 账户
2. 前往 [API 密钥管理页面](https://next.ohmygpt.com/apis/keys)
3. 创建一个拥有管理员权限的新密钥
请注意,出于安全考虑,我们不允许通过 API 创建或修改其他 API 密钥的管理员权限。
## 使用场景
编程式密钥管理的常见场景包括:
* **SaaS 应用**:为每个客户实例自动创建唯一的 API 密钥
* **密钥轮换**:定期轮换 API 密钥以符合安全合规要求
* **用量监控**:追踪密钥使用情况,并自动禁用超出限制的密钥
## 示例用法
所有密钥管理接口都需要在请求头中包含管理员 API 密钥作为 Bearer 令牌。
```python tab="Python"
import requests
# 管理员API密钥(具备管理权限)
ADMIN_API_KEY = "your-admin-api-key"
BASE_URL = "https://api.ohmygpt.com"
# 获取所有API Key
response = requests.post(
f"{BASE_URL}/api/v1/user/admin/get-api-tokens",
headers={
"Authorization": f"Bearer {ADMIN_API_KEY}",
"Content-Type": "application/x-www-form-urlencoded"
}
)
```
```typescript tab="TypeScript"
import axios from 'axios';
const ADMIN_API_KEY = 'your-admin-api-key';
const BASE_URL = 'https://api.ohmygpt.com';
// 获取所有API Key
const response = await axios.post(
`${BASE_URL}/api/v1/user/admin/get-api-tokens`,
{},
{
headers: {
'Authorization': `Bearer ${ADMIN_API_KEY}`,
'Content-Type': 'application/x-www-form-urlencoded'
}
}
);
```
## 使用注意事项
1. **密钥限制**:每个用户最多可创建 5000 个 API 密钥,超出则会报错
2. **管理员权限**:出于安全考虑,不允许通过 API 创建或修改其他 API 密钥的管理员权限
3. **请求限制**:
* 创建/修改/删除密钥:10 QPS
* 查询所有密钥:1 QPS
4. **安全建议**:
* 定期轮换 API 密钥
* 为不同的应用或服务使用不同的 API 密钥
* 设置适当的使用限额,防止异常消耗
file: ./content/docs/features/thinking.en.mdx
meta: {
"title": "Disabling/Enabling Thinking",
"description": "Disable or enable the model's thinking function",
"icon": "Sparkle"
}
You can enable thinking by adding a suffix:
```
// [!code word:-thinking-enabled]
claude-sonnet-4-0-thinking-enabled
```
Supported Models:
* `claude-sonnet-4-0`
* `claude-sonnet-4-20250514`
* `claude-opus-4-0`
* `claude-opus-4-20250514`
***
You can disable thinking by adding a suffix:
```
// [!code word:-thinking-disabled]
gemini-2.5-flash-preview-05-20-thinking-disabled
```
Alternatively, you can disable thinking by passing the parameter `reasoning_effort = none`
file: ./content/docs/features/thinking.mdx
meta: {
"title": "禁止/启用思考",
"description": "禁止或启用模型的思考功能",
"icon": "Sparkle"
}
可通过增加后缀启用思考:
```
// [!code word:-thinking-enabled]
claude-sonnet-4-0-thinking-enabled
```
支持的模型:
* `claude-sonnet-4-0`
* `claude-sonnet-4-20250514`
* `claude-opus-4-0`
* `claude-opus-4-20250514`
***
可通过增加后缀禁止思考:
```
// [!code word:-thinking-disabled]
gemini-2.5-flash-preview-05-20-thinking-disabled
```
也可通过传递参数禁止思考 `reasoning_effort = none`
file: ./content/docs/features/tool-calling.en.mdx
meta: {
"title": "Tool Calling",
"description": "Use tools in your prompts",
"icon": "Hammer"
}
Tool calling (also known as function calling) enables LLMs to access external tools. The LLM doesn't directly call the tool, but instead suggests a tool to call. The user then calls the tool separately and provides the results to the LLM. Finally, the LLM formats its response as an answer to the user's original question.
OhMyGPT standardizes the tool calling interface between models and providers.
For an introduction on how tool calling works in the OpenAI SDK, see [this article](https://platform.openai.com/docs/guides/function-calling?api-mode=chat), or if you prefer learning from complete end-to-end examples, continue reading.
## Tool Calling Example
Here's Python code that enables LLMs to call an external API—in this case, the Project Gutenberg API to search for books.
```python tab="Python"
import json, requests
from openai import OpenAI
OMG_API_KEY = f""
# You can use any model that supports tool calling
MODEL = "gemini-2.0-flash-001"
openai_client = OpenAI(
base_url="https://api.ohmygpt.com/v1",
api_key=OMG_API_KEY,
)
task = "What are the titles of some James Joyce books?"
messages = [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": task,
}
]
```
```typescript tab="TypeScript"
const response = await fetch('https://api.ohmygpt.com/v1/chat/completions', {
method: 'POST',
headers: {
Authorization: `Bearer `,
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gemini-2.0-flash-001',
messages: [
{ role: 'system', content: 'You are a helpful assistant.' },
{
role: 'user',
content: 'What are the titles of some James Joyce books?',
},
],
}),
});
```
## Defining the Tool
Next, we define the tool to call. Remember, the tool will be requested by the LLM, but the code we write here is ultimately responsible for executing the call and returning the results to the LLM.
```python tab="Python"
def search_gutenberg_books(search_terms):
search_query = " ".join(search_terms)
url = "https://gutendex.com/books"
response = requests.get(url, params={"search": search_query})
simplified_results = []
for book in response.json().get("results", []):
simplified_results.append({
"id": book.get("id"),
"title": book.get("title"),
"authors": book.get("authors")
})
return simplified_results
tools = [
{
"type": "function",
"function": {
"name": "search_gutenberg_books",
"description": "Search for books in the Project Gutenberg library based on specified search terms",
"parameters": {
"type": "object",
"properties": {
"search_terms": {
"type": "array",
"items": {
"type": "string"
},
"description": "List of search terms to find books in the Gutenberg library (e.g. ['dickens', 'great'] to search for books by Dickens with 'great' in the title)"
}
},
"required": ["search_terms"]
}
}
}
]
TOOL_MAPPING = {
"search_gutenberg_books": search_gutenberg_books
}
```
```typescript tab="TypeScript"
async function searchGutenbergBooks(searchTerms: string[]): Promise {
const searchQuery = searchTerms.join(' ');
const url = 'https://gutendex.com/books';
const response = await fetch(`${url}?search=${searchQuery}`);
const data = await response.json();
return data.results.map((book: any) => ({
id: book.id,
title: book.title,
authors: book.authors,
}));
}
const tools = [
{
type: 'function',
function: {
name: 'search_gutenberg_books',
description:
'Search for books in the Project Gutenberg library based on specified search terms',
parameters: {
type: 'object',
properties: {
search_terms: {
type: 'array',
items: {
type: 'string',
},
description:
"List of search terms to find books in the Gutenberg library (e.g. ['dickens', 'great'] to search for books by Dickens with 'great' in the title)",
},
},
required: ['search_terms'],
},
},
},
];
const TOOL_MAPPING = {
searchGutenbergBooks,
};
```
Note that the "tool" is just a plain function. We then write a JSON "specification" that's compatible with the OpenAI function calling parameters. We'll pass that specification to the LLM so it knows this tool is available and how to use it. It will request the tool, and any parameters, when needed. Then we'll handle the tool calling locally, make the function call, and return the results to the LLM.
## Tool Usage and Tool Results
Let's make our first call to the model:
```python tab="Python"
request_1 = {
"model": gemini-2.0-flash-001,
"tools": tools,
"messages": messages
}
response_1 = openai_client.chat.completions.create(**request_1).message
```
```typescript tab="TypeScript"
const response = await fetch('https://api.ohmygpt.com/v1/chat/completions', {
method: 'POST',
headers: {
Authorization: `Bearer `,
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gemini-2.0-flash-001',
tools,
messages,
}),
});
```
The LLM responds with a completion reason of tool\_calls, and an array of tool\_calls. In a generic LLM response handler, you'd want to check the completion reason before processing tool calls, but here we'll assume that's the case. Let's go ahead and handle the tool call:
```python tab="Python"
# 附加对消息数组的响应,以便LLM具有完整的上下文
# 很容易忘记此步骤!
messages.append(response_1)
# 现在我们处理请求的工具调用,并使用我们的书籍查找工具
for tool_call in response_1.tool_calls:
'''
In this case we only provided one tool, so we know what function to call.
When providing multiple tools, you can inspect `tool_call.function.name`
to figure out what function you need to call locally.
'''
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
tool_response = TOOL_MAPPING[tool_name](**tool_args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_name,
"content": json.dumps(tool_response),
})
```
```typescript tab="TypeScript"
// Append the response to the messages array so the LLM has the full context
// It's easy to forget this step!
messages.push(response);
// Now we handle the requested tool call, and use our book lookup tool
for (const toolCall of response.toolCalls) {
const toolName = toolCall.function.name;
const toolArgs = JSON.parse(toolCall.function.arguments);
const toolResponse = await TOOL_MAPPING[toolName](toolArgs);
messages.push({
role: 'tool',
toolCallId: toolCall.id,
name: toolName,
content: JSON.stringify(toolResponse),
});
}
```
The messages array now contains:
1. Our original request
2. The LLM's response (containing the tool call request)
3. The results of the tool call (a json object returned from the Project Gutenberg API)
Now we can make our second call and, hopefully, get our results!
```python tab="Python"
request_2 = {
"model": MODEL,
"messages": messages,
"tools": tools
}
response_2 = openai_client.chat.completions.create(**request_2)
print(response_2.choices[0].message.content)
```
```typescript tab="TypeScript"
const response = await fetch('https://api.ohmygpt.com/v1/chat/completions', {
method: 'POST',
headers: {
Authorization: `Bearer `,
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gemini-2.0-flash-001',
messages,
tools,
}),
});
const data = await response.json();
console.log(data.choices[0].message.content);
```
The output will be something like:
```
Here are some books by James Joyce:
* *Ulysses*
* *Dubliners*
* *A Portrait of the Artist as a Young Man*
* *Chamber Music*
* *Exiles: A Play in Three Acts*
```
We did it! We've successfully used a tool in a prompt.
file: ./content/docs/features/tool-calling.mdx
meta: {
"title": "工具调用",
"description": "在你的提示中使用工具",
"icon": "Hammer"
}
工具调用(也称为函数调用)使 LLM 能够访问外部工具。LLM 并不直接调用工具,而是建议要调用的工具。用户随后单独调用该工具,并将结果提供给 LLM。最后,LLM 将响应格式化为对用户原始问题的答案。
OhMyGPT 在模型和提供者之间标准化了工具调用接口。
有关工具调用在 OpenAI SDK 中如何工作的入门,请参阅[本文](https://platform.openai.com/docs/guides/function-calling?api-mode=chat),或者如果您更喜欢从完整的端到端示例中学习,请继续阅读。
## 工具调用示例
这里是 Python 代码,它使 LLMs 能够调用外部 API——在这种情况下是古腾堡计划,以搜索书籍。
```python tab="Python"
import json, requests
from openai import OpenAI
OMG_API_KEY = f""
# You can use any model that supports tool calling
MODEL = "gemini-2.0-flash-001"
openai_client = OpenAI(
base_url="https://api.ohmygpt.com/v1",
api_key=OMG_API_KEY,
)
task = "What are the titles of some James Joyce books?"
messages = [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": task,
}
]
```
```typescript tab="TypeScript"
const response = await fetch('https://api.ohmygpt.com/v1/chat/completions', {
method: 'POST',
headers: {
Authorization: `Bearer `,
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gemini-2.0-flash-001',
messages: [
{ role: 'system', content: 'You are a helpful assistant.' },
{
role: 'user',
content: 'What are the titles of some James Joyce books?',
},
],
}),
});
```
## 定义工具
接下来,我们定义要调用的工具。请记住,该工具将由 LLM 请求,但我们在这里编写的代码最终负责执行调用并将结果返回给 LLM。
```python tab="Python"
def search_gutenberg_books(search_terms):
search_query = " ".join(search_terms)
url = "https://gutendex.com/books"
response = requests.get(url, params={"search": search_query})
simplified_results = []
for book in response.json().get("results", []):
simplified_results.append({
"id": book.get("id"),
"title": book.get("title"),
"authors": book.get("authors")
})
return simplified_results
tools = [
{
"type": "function",
"function": {
"name": "search_gutenberg_books",
"description": "Search for books in the Project Gutenberg library based on specified search terms",
"parameters": {
"type": "object",
"properties": {
"search_terms": {
"type": "array",
"items": {
"type": "string"
},
"description": "List of search terms to find books in the Gutenberg library (e.g. ['dickens', 'great'] to search for books by Dickens with 'great' in the title)"
}
},
"required": ["search_terms"]
}
}
}
]
TOOL_MAPPING = {
"search_gutenberg_books": search_gutenberg_books
}
```
```typescript tab="TypeScript"
async function searchGutenbergBooks(searchTerms: string[]): Promise {
const searchQuery = searchTerms.join(' ');
const url = 'https://gutendex.com/books';
const response = await fetch(`${url}?search=${searchQuery}`);
const data = await response.json();
return data.results.map((book: any) => ({
id: book.id,
title: book.title,
authors: book.authors,
}));
}
const tools = [
{
type: 'function',
function: {
name: 'search_gutenberg_books',
description:
'Search for books in the Project Gutenberg library based on specified search terms',
parameters: {
type: 'object',
properties: {
search_terms: {
type: 'array',
items: {
type: 'string',
},
description:
"List of search terms to find books in the Gutenberg library (e.g. ['dickens', 'great'] to search for books by Dickens with 'great' in the title)",
},
},
required: ['search_terms'],
},
},
},
];
const TOOL_MAPPING = {
searchGutenbergBooks,
};
```
请注意,“tool”只是一个普通的函数。然后我们编写一个与 OpenAI 函数调用参数兼容的 JSON “规范”。我们将把该规范传递给 LLM,以便它知道这个工具是可用的以及如何使用它。它将在需要时请求该工具,以及任何参数。然后我们将在本地处理工具调用,进行函数调用,并将结果返回给 LLM。
## 工具使用和工具结果
让我们向模型发出第一个调用:
```python tab="Python"
request_1 = {
"model": gemini-2.0-flash-001,
"tools": tools,
"messages": messages
}
response_1 = openai_client.chat.completions.create(**request_1).message
```
```typescript tab="TypeScript"
const response = await fetch('https://api.ohmygpt.com/v1/chat/completions', {
method: 'POST',
headers: {
Authorization: `Bearer `,
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gemini-2.0-flash-001',
tools,
messages,
}),
});
```
LLM 以 tool\_calls 的完成原因和一个 tool\_calls 数组进行响应。在通用的 LLM 响应处理程序中,您会想在处理工具调用之前检查完成原因,但在这里我们将假设情况是这样的。让我们继续,处理工具调用:
```python tab="Python"
# 附加对消息数组的响应,以便LLM具有完整的上下文
# 很容易忘记此步骤!
messages.append(response_1)
# 现在我们处理请求的工具调用,并使用我们的书籍查找工具
for tool_call in response_1.tool_calls:
'''
In this case we only provided one tool, so we know what function to call.
When providing multiple tools, you can inspect `tool_call.function.name`
to figure out what function you need to call locally.
'''
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
tool_response = TOOL_MAPPING[tool_name](**tool_args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_name,
"content": json.dumps(tool_response),
})
```
```typescript tab="TypeScript"
// 附加对消息数组的响应,以便LLM具有完整的上下文
// 很容易忘记此步骤!
messages.push(response);
// 现在我们处理请求的工具调用,并使用我们的书籍查找工具
for (const toolCall of response.toolCalls) {
const toolName = toolCall.function.name;
const toolArgs = JSON.parse(toolCall.function.arguments);
const toolResponse = await TOOL_MAPPING[toolName](toolArgs);
messages.push({
role: 'tool',
toolCallId: toolCall.id,
name: toolName,
content: JSON.stringify(toolResponse),
});
}
```
消息数组现在包含:
1. 我们的原始请求
2. LLM 的响应(包含工具调用请求)
3. 工具调用的结果(从古腾堡项目 API 返回的 json 对象)
现在,我们可以进行第二次调用,并希望获得我们的结果!
```python tab="Python"
request_2 = {
"model": MODEL,
"messages": messages,
"tools": tools
}
response_2 = openai_client.chat.completions.create(**request_2)
print(response_2.choices[0].message.content)
```
```typescript tab="TypeScript"
const response = await fetch('https://api.ohmygpt.com/v1/chat/completions', {
method: 'POST',
headers: {
Authorization: `Bearer `,
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'gemini-2.0-flash-001',
messages,
tools,
}),
});
const data = await response.json();
console.log(data.choices[0].message.content);
```
输出将类似于:
```
Here are some books by James Joyce:
* *Ulysses*
* *Dubliners*
* *A Portrait of the Artist as a Young Man*
* *Chamber Music*
* *Exiles: A Play in Three Acts*
```
我们做到了!我们成功地在提示中使用了一个工具。
file: ./content/docs/features/web-search.en.mdx
meta: {
"title": "Web Search",
"description": "Model-embedded search functionality",
"icon": "Search"
}
You can activate the search function by adding `/gs` or `gs/` at the beginning of a message.
```
/gs What is a "Cheezburger"?
```
**How to Enable:** Enable the embedded search function by checking `chat-completions-with-gs` in [`API Keys - Model Permissions`](https://next.ohmygpt.com/apis/keys).
* Currently only supports `OpenAI`'s `3.5` / `4` / `4 Turbo` series models (excluding 32k and Azure).
* Currently only supports the Google Search API. More models and more optional search service providers will be integrated later.
file: ./content/docs/features/web-search.mdx
meta: {
"title": "Web 搜索",
"description": "模型内嵌搜索功能",
"icon": "Search"
}
你可以通过在消息开头添加 `/gs` 或 `gs/` 来激活搜索功能
```
/gs 什么是“芝士雪豹”?
```
**启用方式:** 在 [`API密钥 - 模型权限`](https://next.ohmygpt.com/apis/keys) 中勾选 `chat-completions-with-gs` 来启用内嵌搜索功能
* 目前仅支持 `OpenAI` 的 `3.5` / `4` / `4 Turbo` 系列模型(32k和Azure除外)
* 目前仅支持谷歌搜索API, 后面会接入更多模型以及更多可选的搜索服务提供方
file: ./content/docs/orders/bot.en.mdx
meta: {
"title": "Telegram Bot",
"description": "Telegram Bot Usage Guide",
"icon": "Bot"
}
# Overview
To make it more convenient for users to access our services via Telegram and other messaging apps, we developed a Telegram Bot.
Bot Username: `@getfunbot`
Bot Link: [https://t.me/getfunbot](https://t.me/getfunbot)
***
## Bind Your OhMyGPT Account
1. **If you already have an OhMyGPT account**
Type the `/bind` command to begin binding your existing OhMyGPT account:
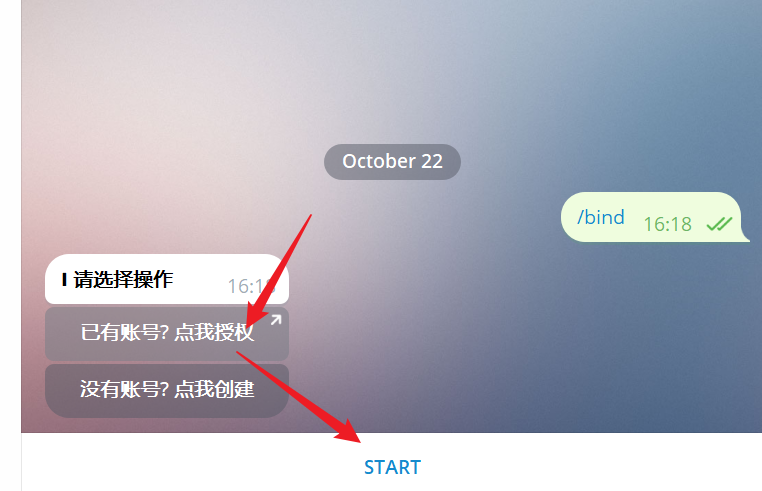
After being redirected in the browser, click "Start". Once you see the success message, you can begin using the bot.
2. **If you don’t have an OhMyGPT account**
Click the "Create Now" button to quickly register a virtual OhMyGPT account using your Telegram user ID. You can start using the service right away and later bind it to your own account.
***
## Bot Settings
Command: `/set`
***
## Check Your Balance
***
## Get an API Key
***
## Create a Stripe Order

***
## Start a Chat
You can start chatting directly in the bot’s dialog window, or add the bot to your group chat (the bot needs access to group messages and should generally be granted admin privileges).
In private or group chats, use:
Command:
`//` + `ModelName (optional)` + Question
`/c` + Question
Voice message
When using `/c Question` or `// Question`, it defaults to the `4o-mini` model, which offers good performance at a reasonable cost.
Model names are fuzzy-matched automatically. For example:
`//c35s` will match to model: `claude-3-5-sonnet`
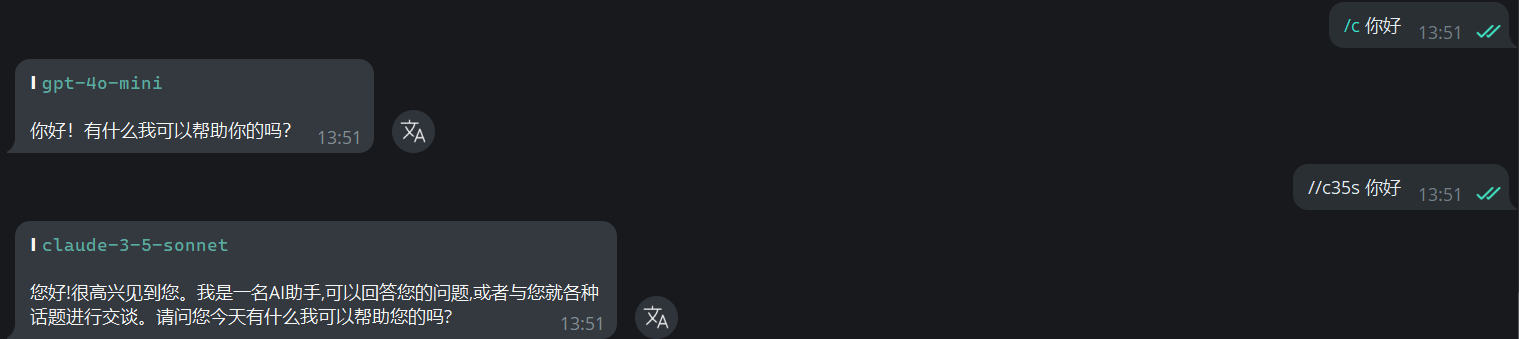

After having a long conversation, remember to use `/newchat` to clear the context and avoid token accumulation which can lead to increased costs.
***
### Find Models
Search for models using keywords:
Command: `/f keyword`
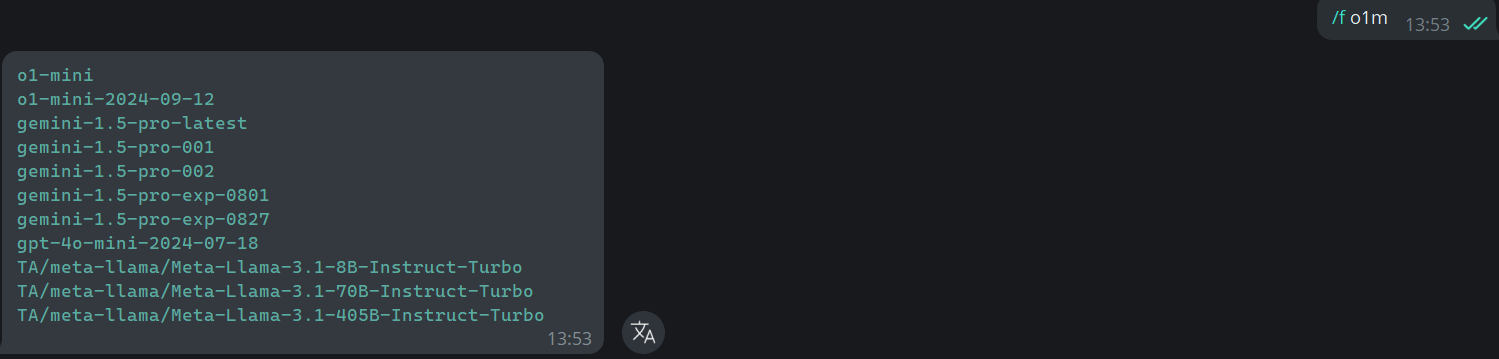
***
## Image Generation
### Flux AI
Use `/flux_` + Flux model name to generate images:
***
### Midjourney
Command: `/mj` + Prompt
***
## Text-to-Speech (TTS)
Command: `/tts` + Prompt
## GPT Text Game
Send `/game` to start playing.
## Other Features
More features are in development. Stay tuned!
file: ./content/docs/orders/bot.mdx
meta: {
"title": "Telegram Bot",
"description": "Telegram Bot使用文档",
"icon": "Bot"
}
# 简介
为方便用户在Telegram等聊天软件中使用本站的服务,因此我们开发了Telegram Bot以供用户使用。
Bot Username: `@getfunbot`
Bot 链接: [https://t.me/getfunbot](https://t.me/getfunbot)
***
## 绑定OhMyGPT账号
1. 如果您已经有了OhMyGPT账户
输入 `/bind` 命令开始绑定您现有的OhMyGPT账户:

浏览器跳转回来,点击Start,提示绑定成功后即可开始使用
2. 如果您没有OhMyGPT账户
您可以点击“点我创建”按钮,直接根据您的Tg用户ID快速创建一个虚拟的OhMyGPT账户,从而快速开始使用,之后可以换绑为您自己的OhMyGPT账户。
***
## Bot设置
指令: `/set`

***
## 查询余额

***
## 获取一个APIKey

***
## 创建Stripe订单

***
## 开始Chat
直接在此Bot的对话框中开始聊天,或者将它拉入您的群聊中(此Bot需要访问群聊消息以便和群聊中的用户交互,一般需要给予群聊管理员权限)
在私聊或群聊中发送
指令:
`//` + `模型名称(可选)` + 问题
`/c` + 问题
`语音`
直接使用 `/c 问题`或`// 问题` 时,会默认使用`4o-mini`,这是一个性价比不错的模型
其中模型名称这里会自动模糊搜索匹配,例如:
`//c35s` 会匹配到模型: `claude-3-5-sonnet`


在进行一段对话后,记得使用 `/newchat` 清理上下文,防止PromptToken累计导致费用逐步升高。
***
### 查找模型
通过关键词查找模型
指令: `/f 关键词`

***
## 图像生成
### Flux AI
输入 `/flux_` + flux模型名即可使用:

***
### Midjourney
指令: `/mj` + 提示词
***
## 语音生成
指令: `/tts` + 提示词
## GPT文字游戏
发送 `/game` 开始游戏
## 其它功能
其它功能正在积极开发中,敬请期待
file: ./content/docs/orders/cloudflare-worker.en.mdx
meta: {
"title": "Self-Hosted Cloudflare Worker Reverse Proxy",
"icon": "Cloud"
}
# Introduction
This article explains how to build a self-hosted API reverse proxy service using Cloudflare Workers, with support for raw API interaction logging and custom model name rewriting.
Some users may wish to customize model names for compatibility with certain quirky clients, or access raw API interaction data for debugging. However, for privacy and compatibility reasons, we prefer not to support these functions directly on the backend. To address this need safely and privately, we’ve designed a lightweight script based on Cloudflare Workers that achieves these goals.
Demo features:
Model rewriting: `claude-3-haiku => claude-3-5-haiku`, `claude-3.5-haiku-8080 => claude-3-5-sonnet`:
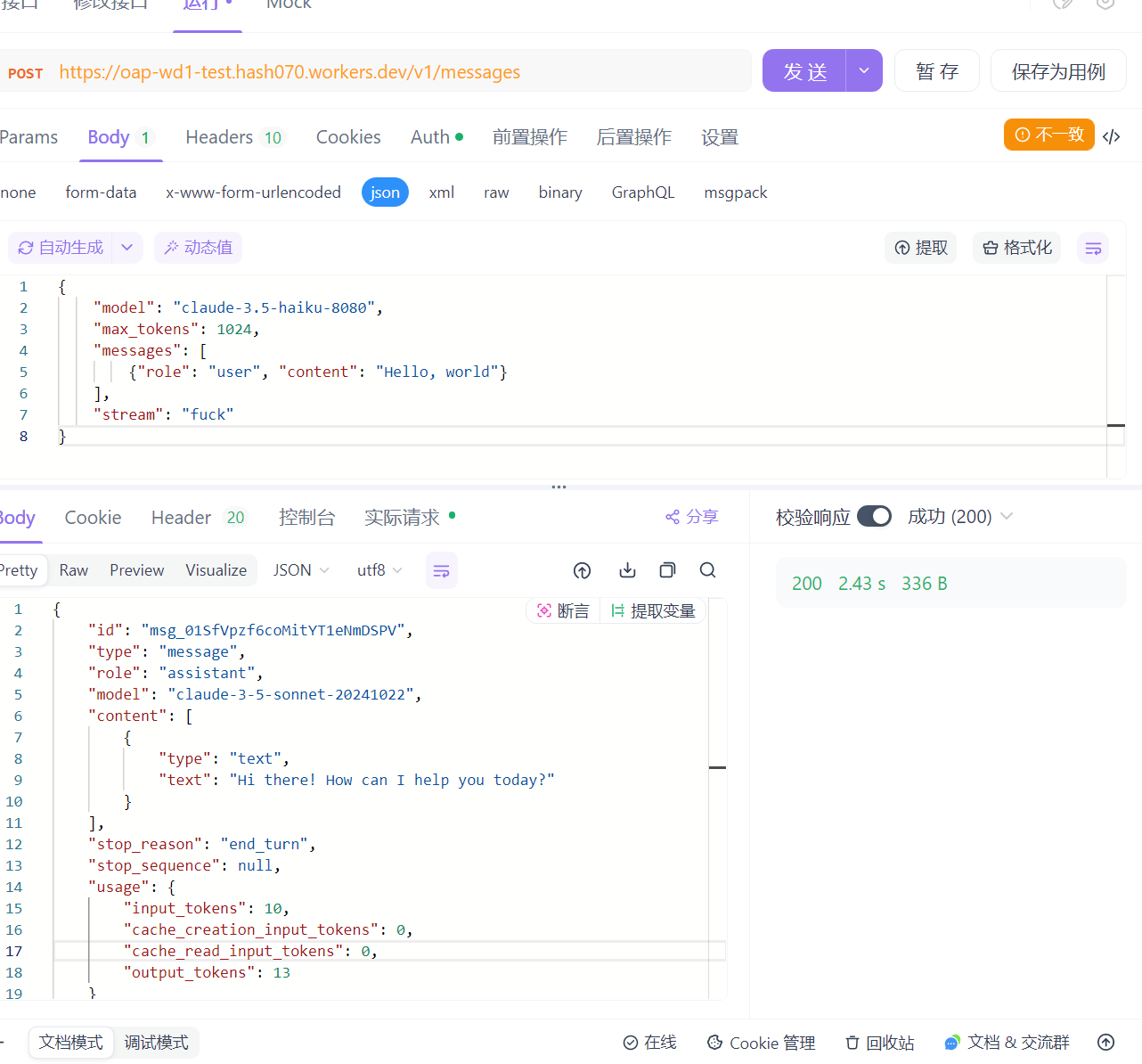
Raw API interaction logging:
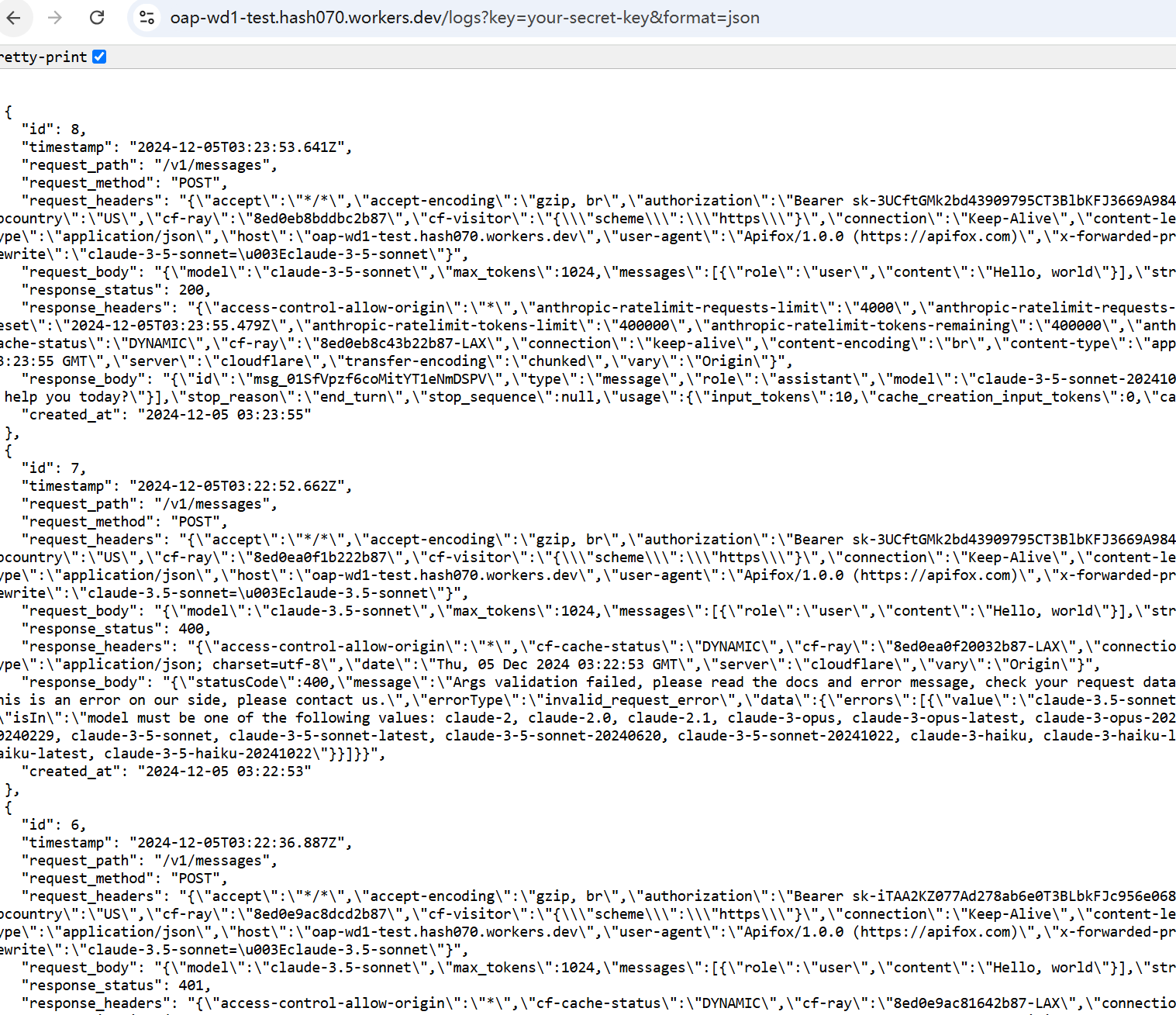
# Setup
## Create a Worker
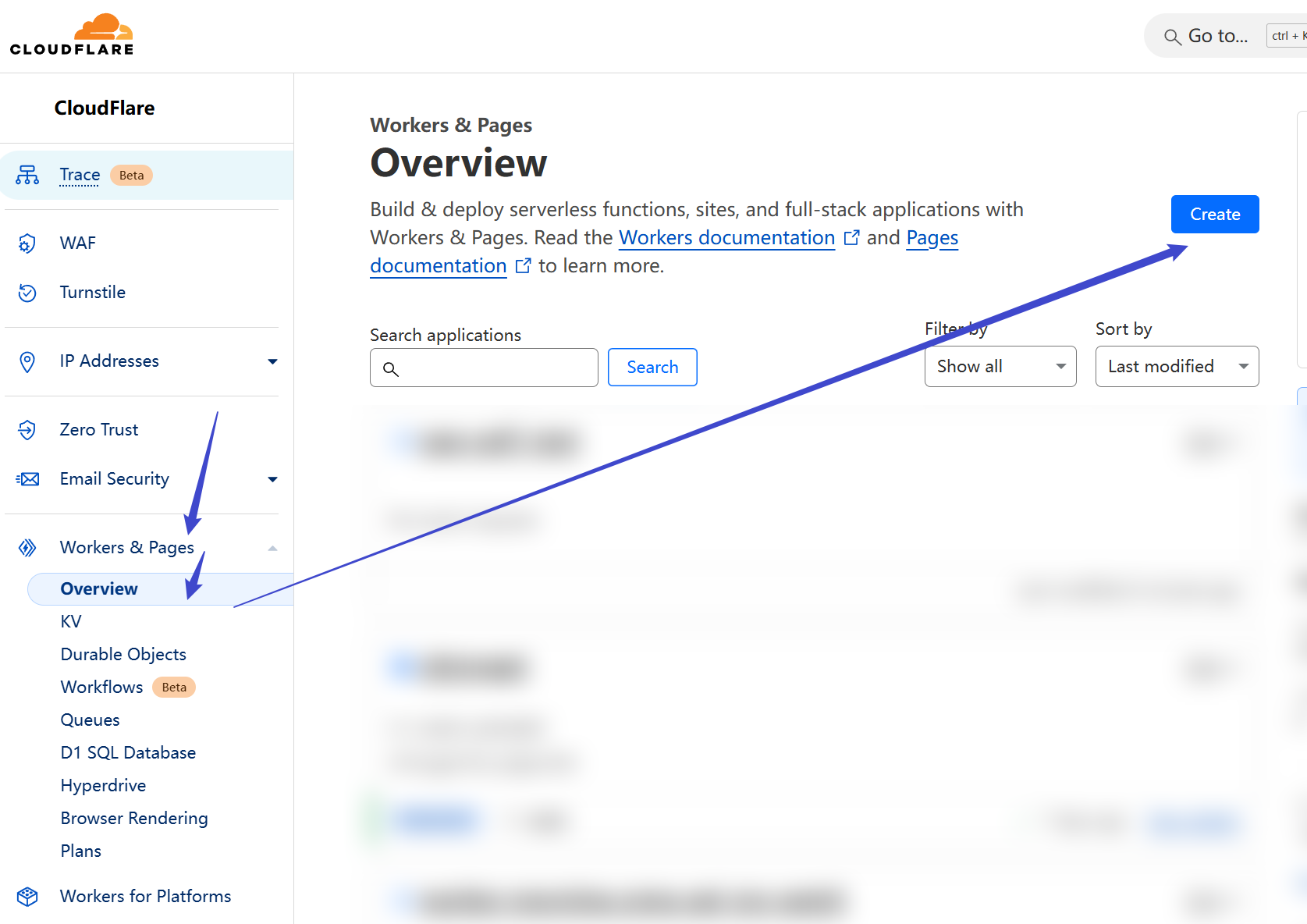
Go to your Cloudflare Dashboard
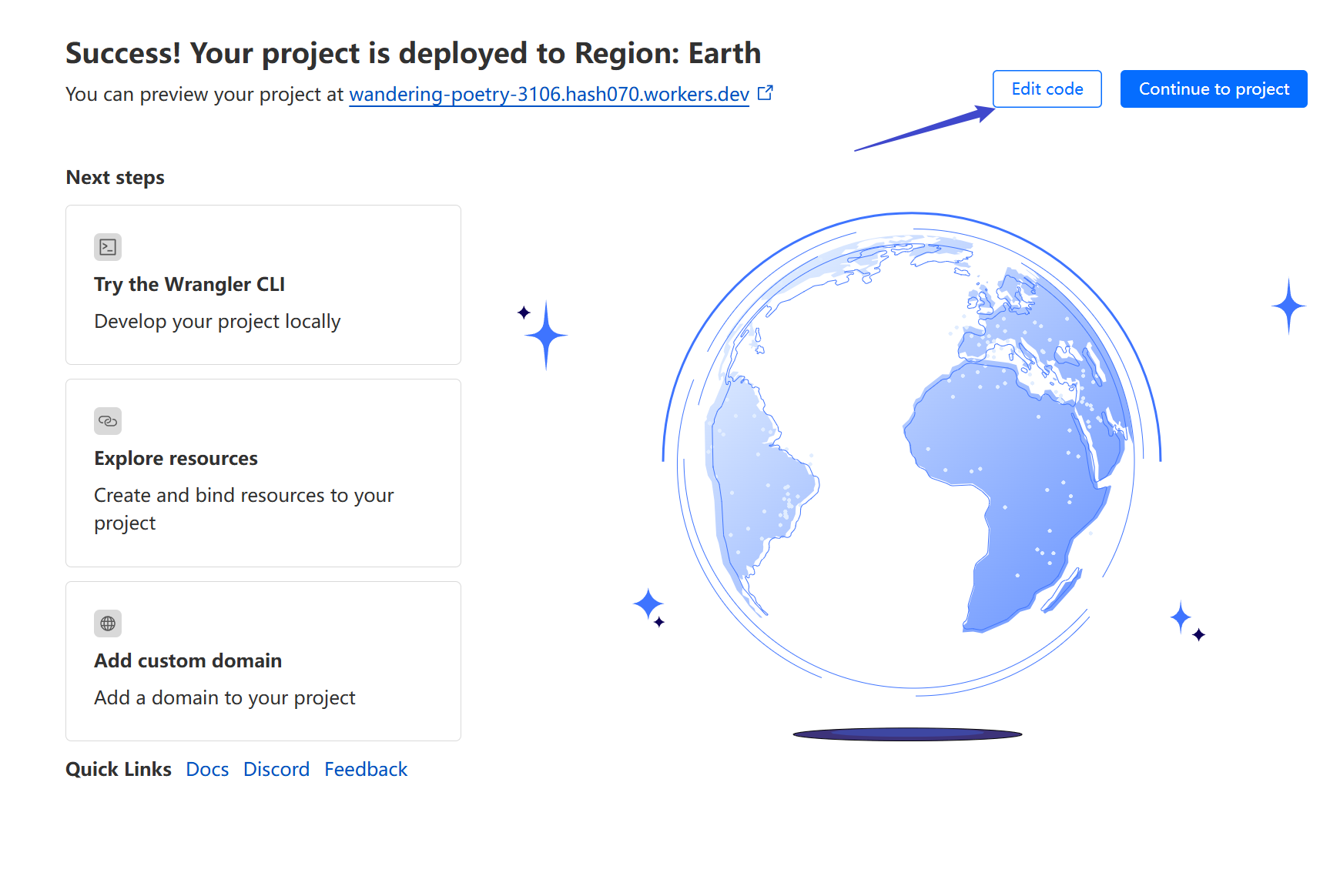
Click `Workers & Pages` => `Overview` => `Create` to create a new Worker
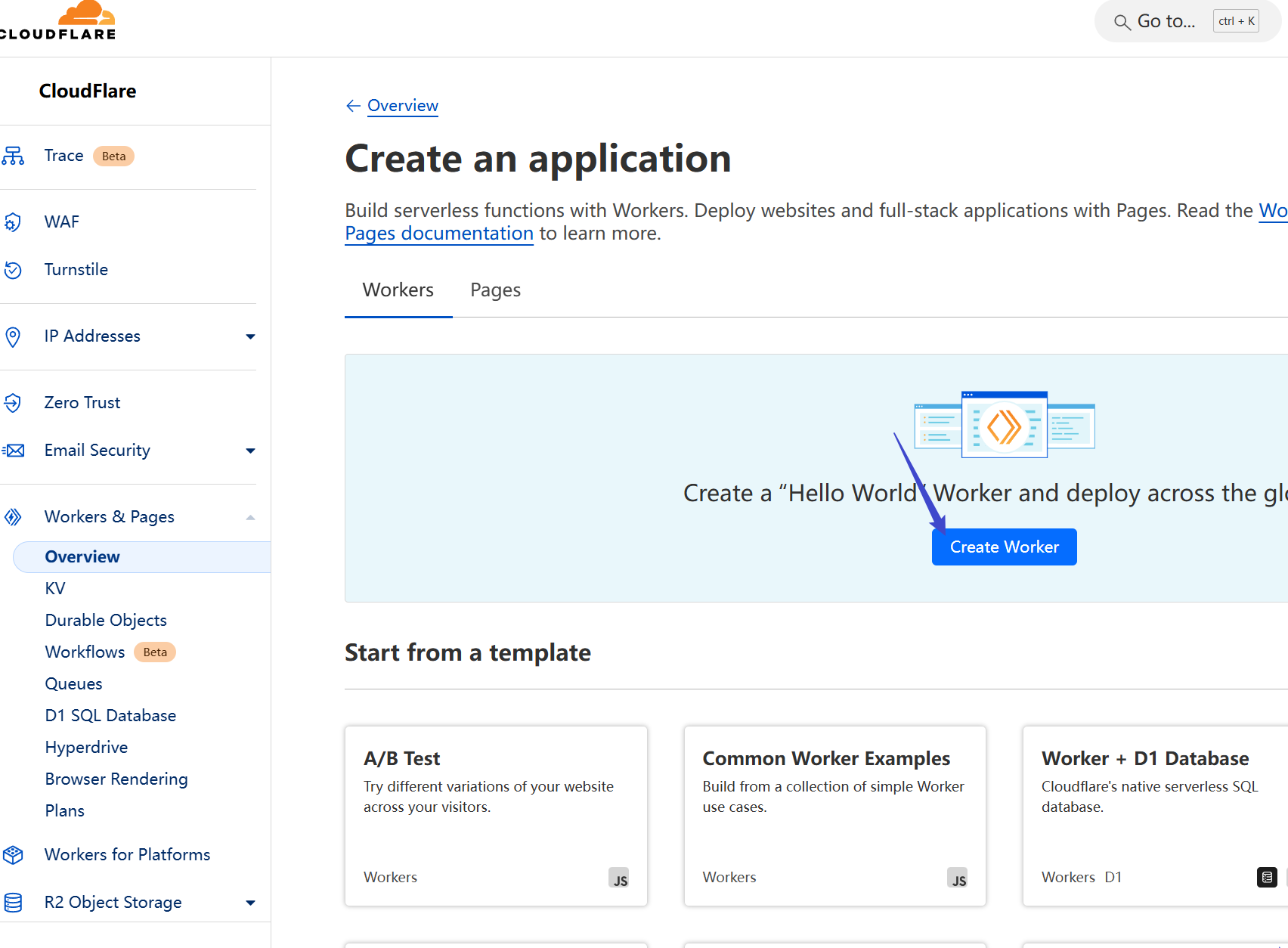
Choose any name and click Create
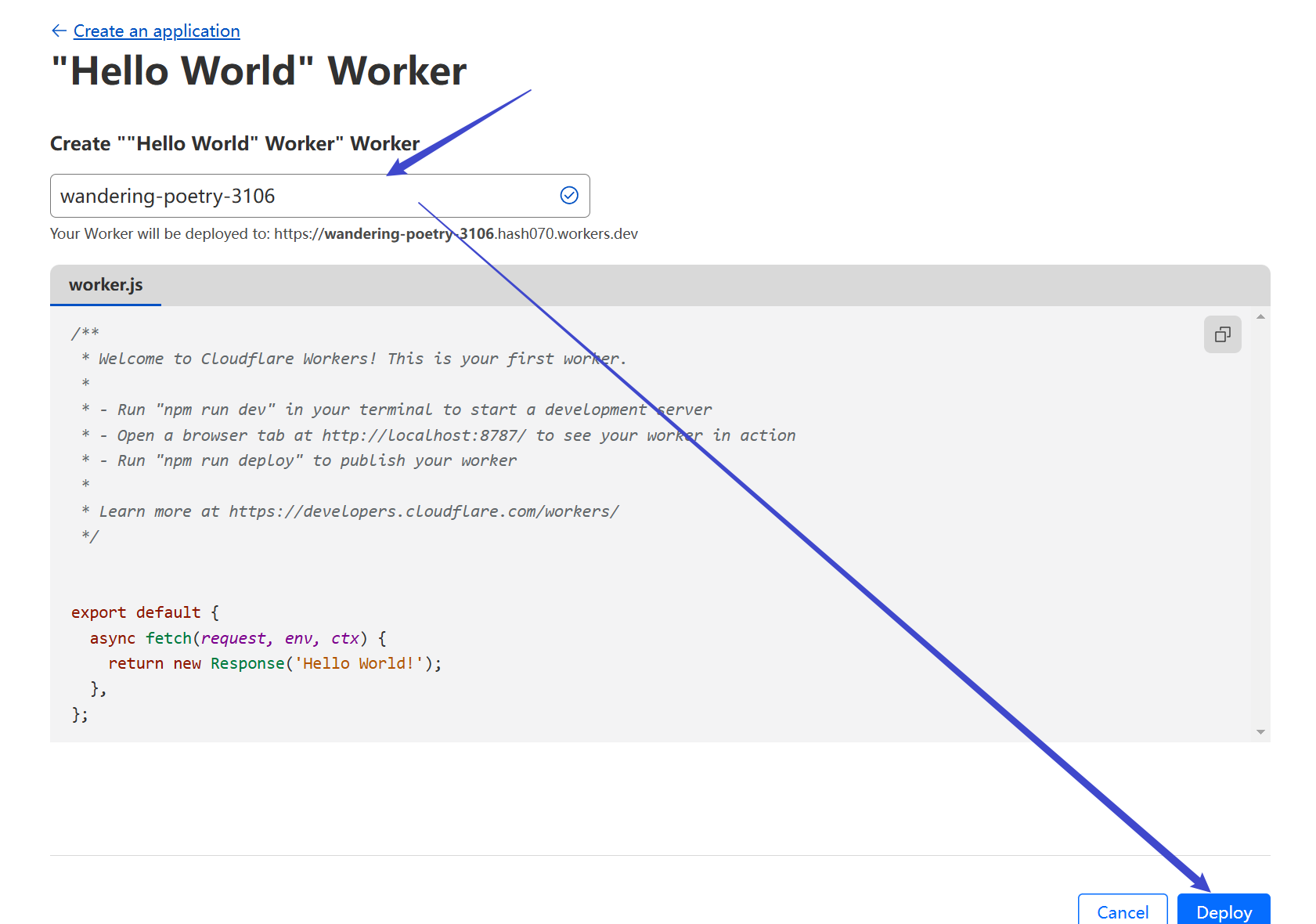
## Edit Worker Code
Click to edit the Worker code:
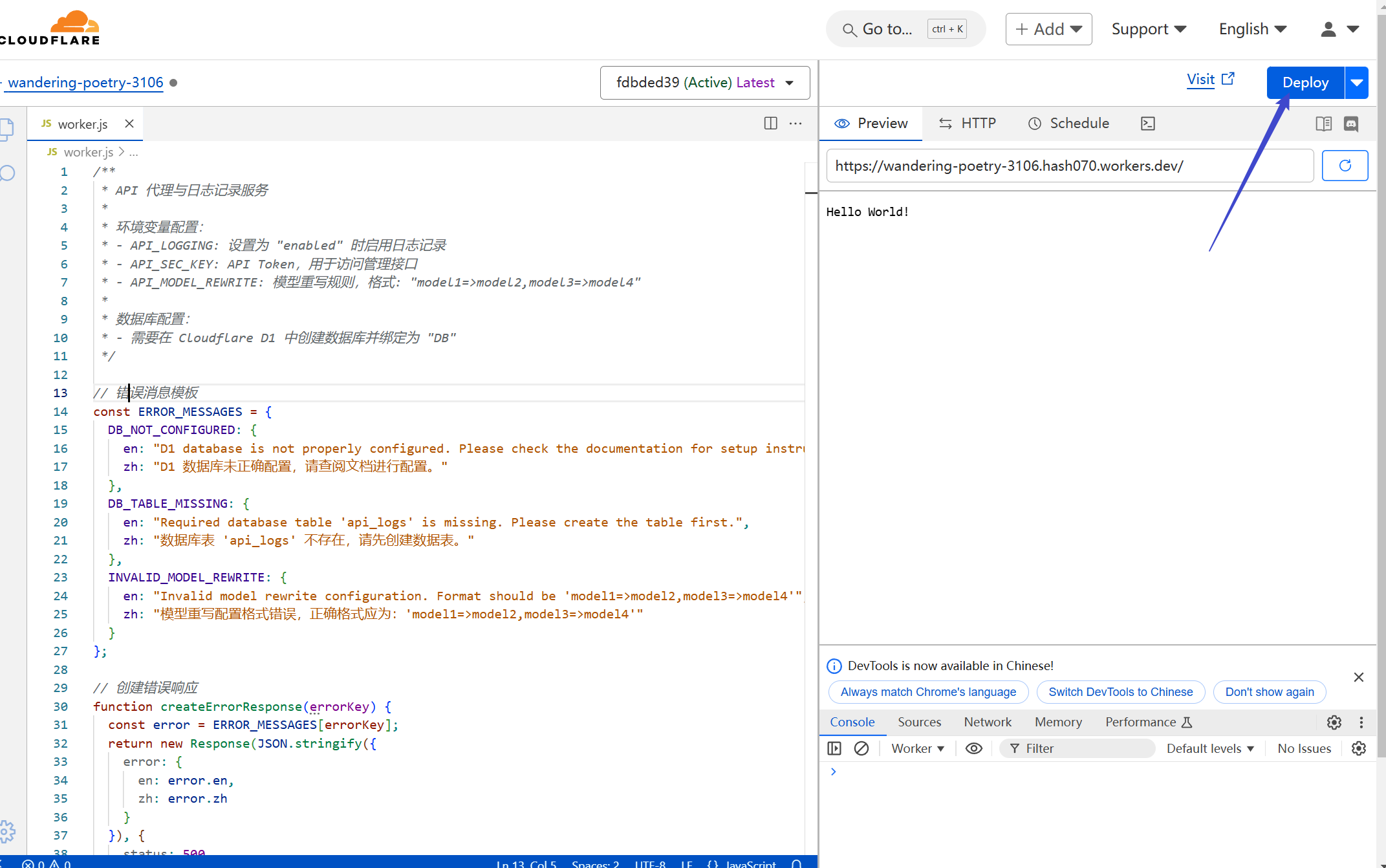
Clear the default code, paste in the full code block below, and click `Deploy` to save and deploy.
```javascript
// ... [Code remains unchanged from original Chinese version; it's JavaScript and self-explanatory] ...
```
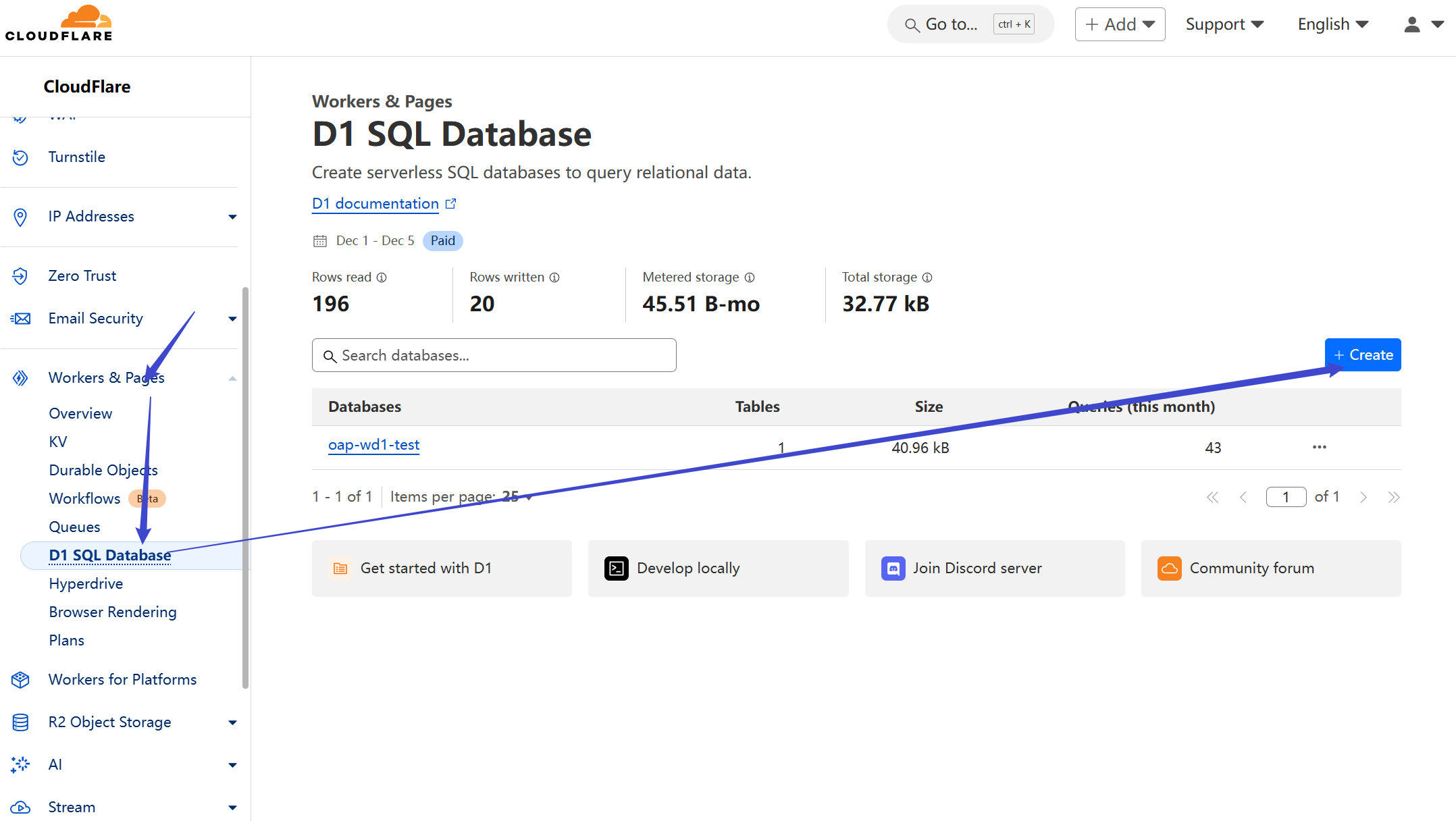
## Create and Initialize D1 Database
Go to `Workers & Pages` => `D1` => Click `Create` to create a new database
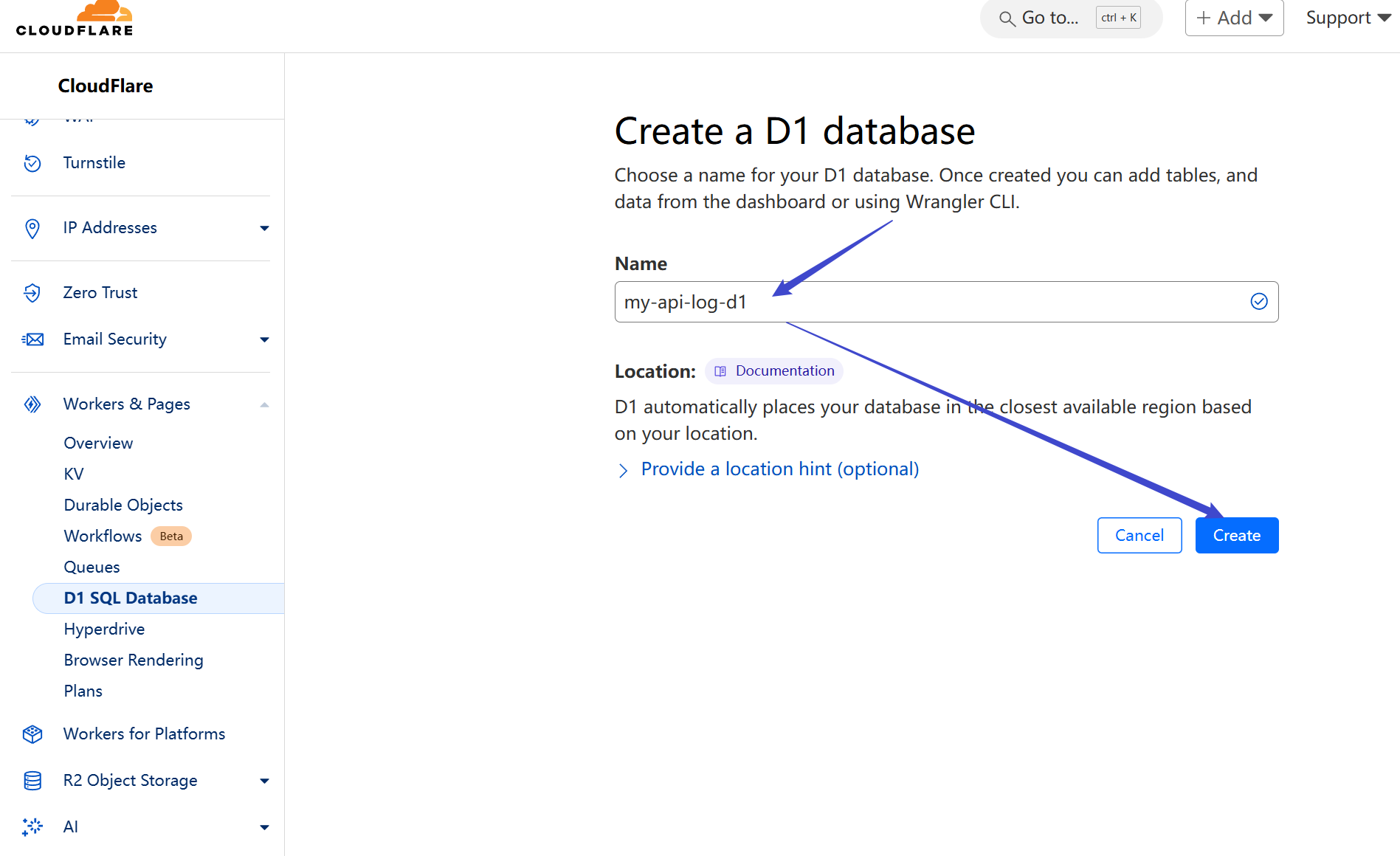
Name it anything you like and click Create
Initialize the database with this SQL:
```
CREATE TABLE IF NOT EXISTS api_logs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT,
request_path TEXT,
request_method TEXT,
request_headers TEXT,
request_body TEXT,
response_status INTEGER,
response_headers TEXT,
response_body TEXT,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
```
Paste the SQL above into the blue box and run it.
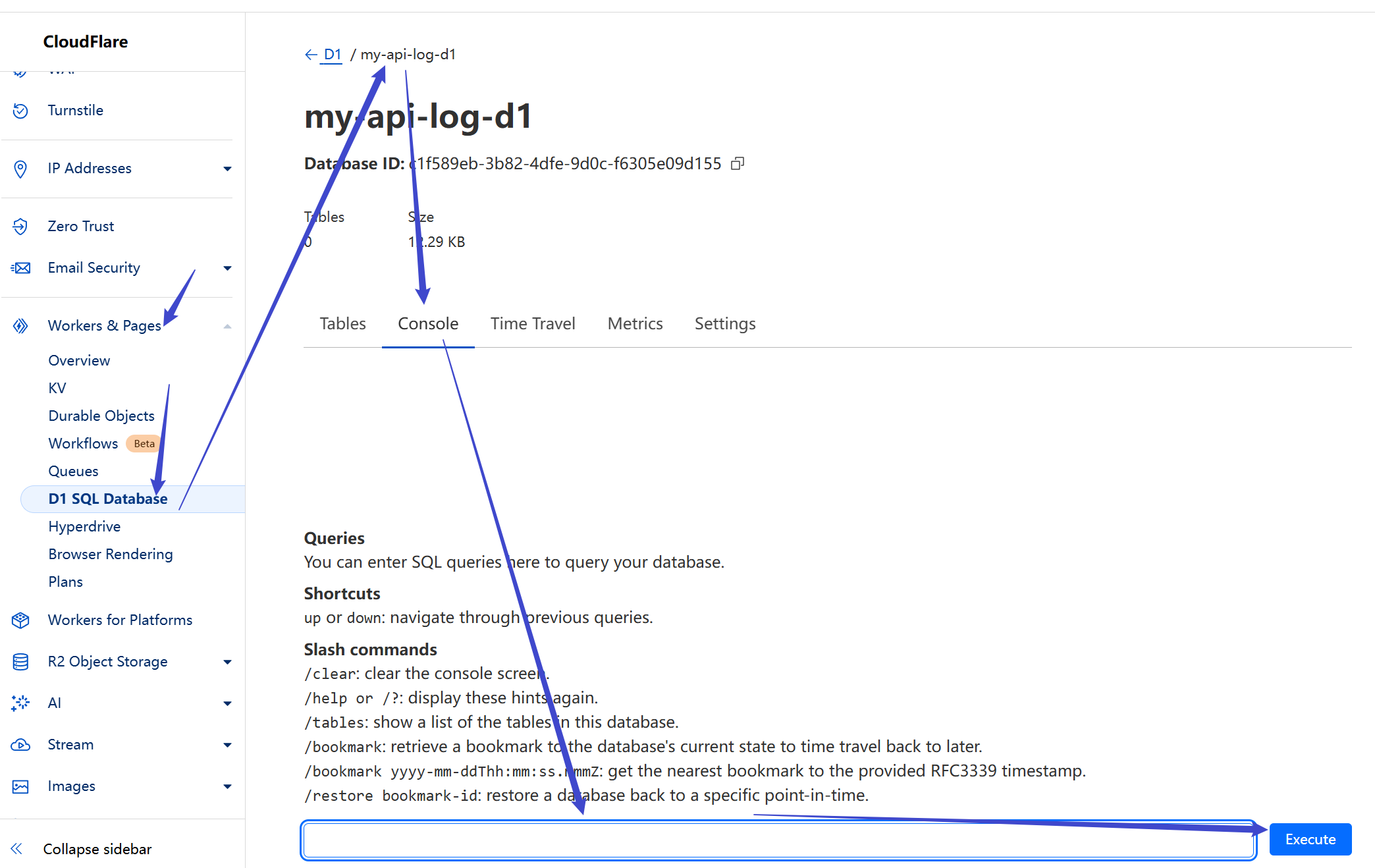
You should see this when it succeeds:

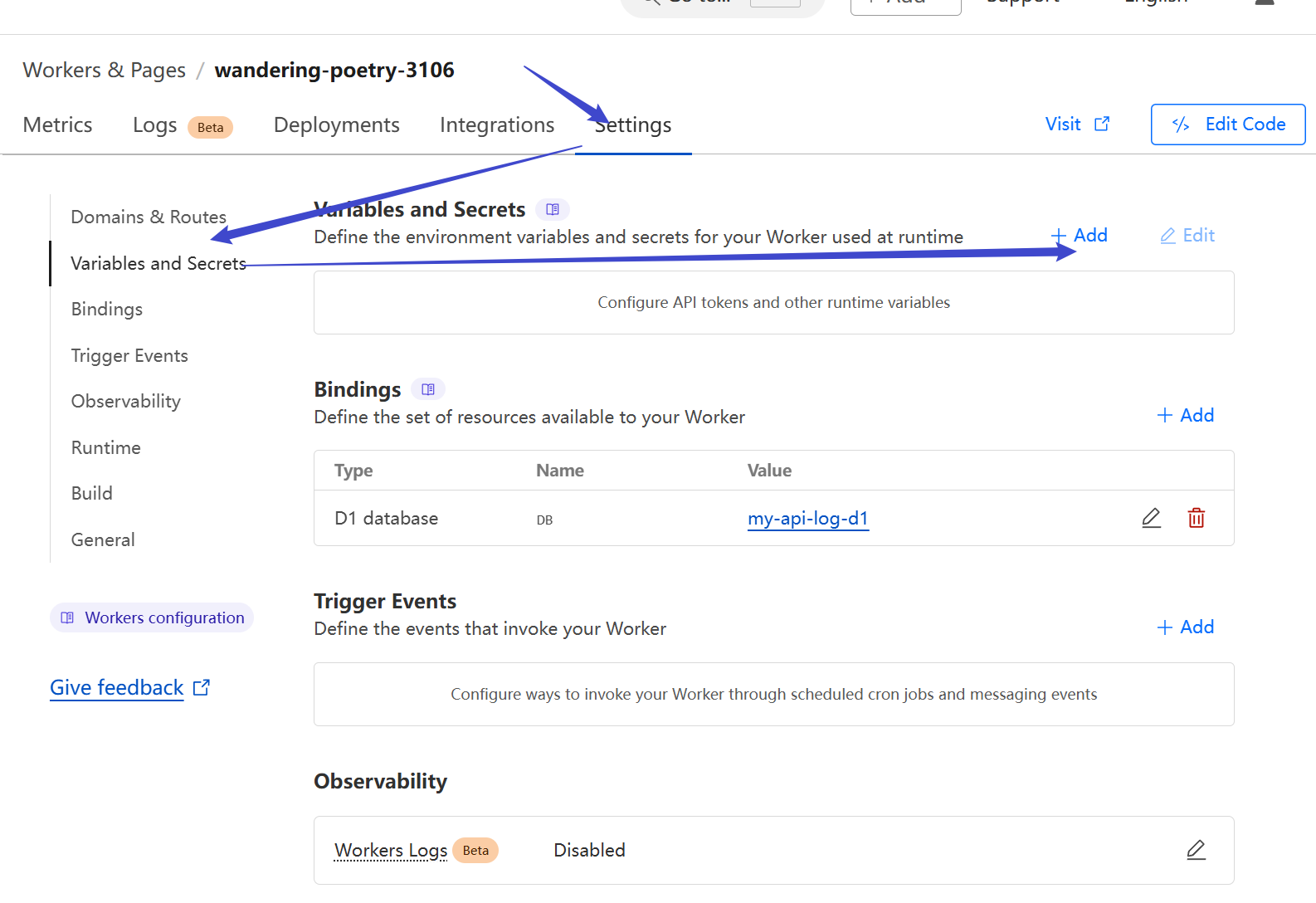
## Configure the Worker
### Bind D1 Database
Find the Worker you created:
Bind the D1 database:

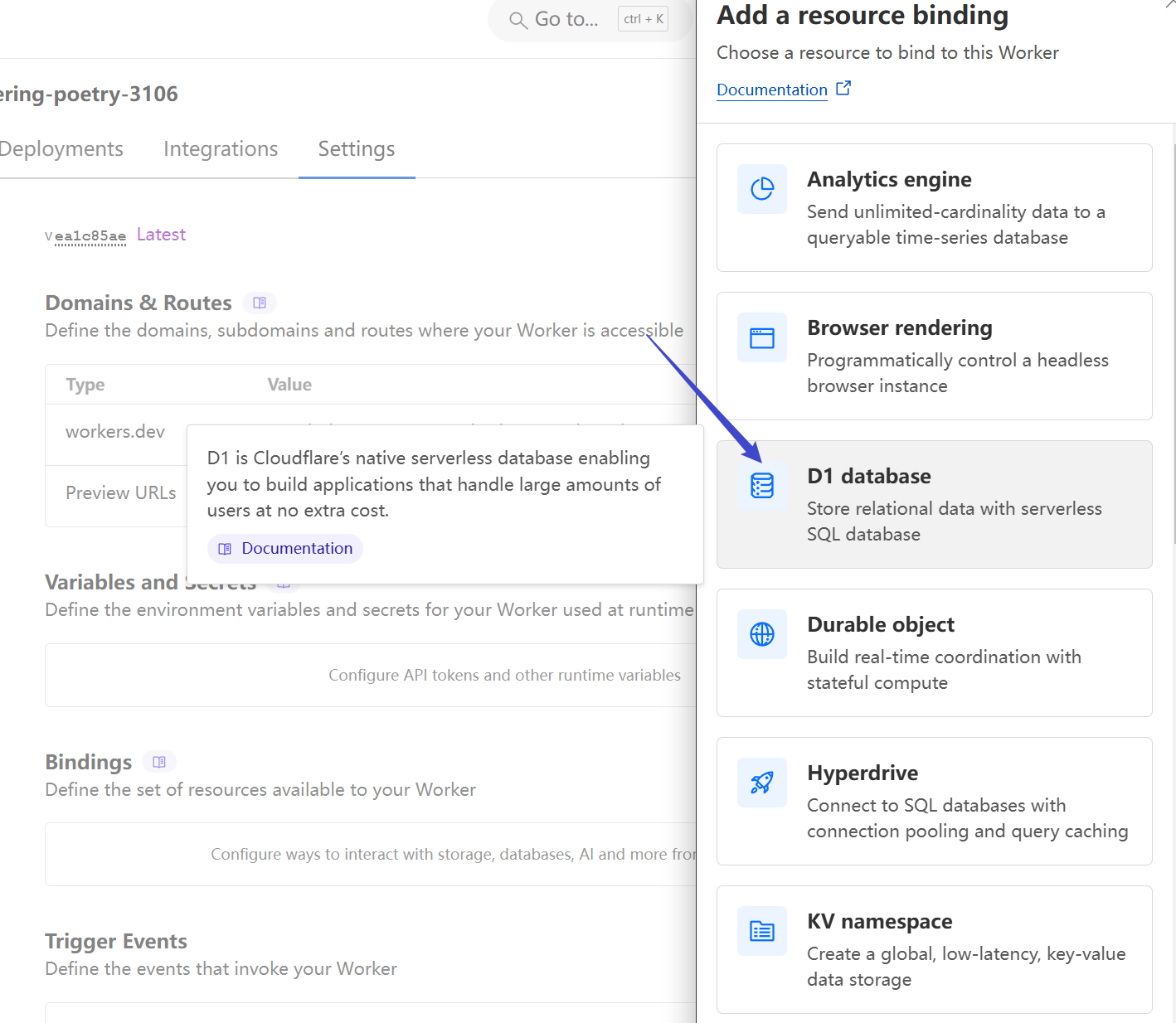
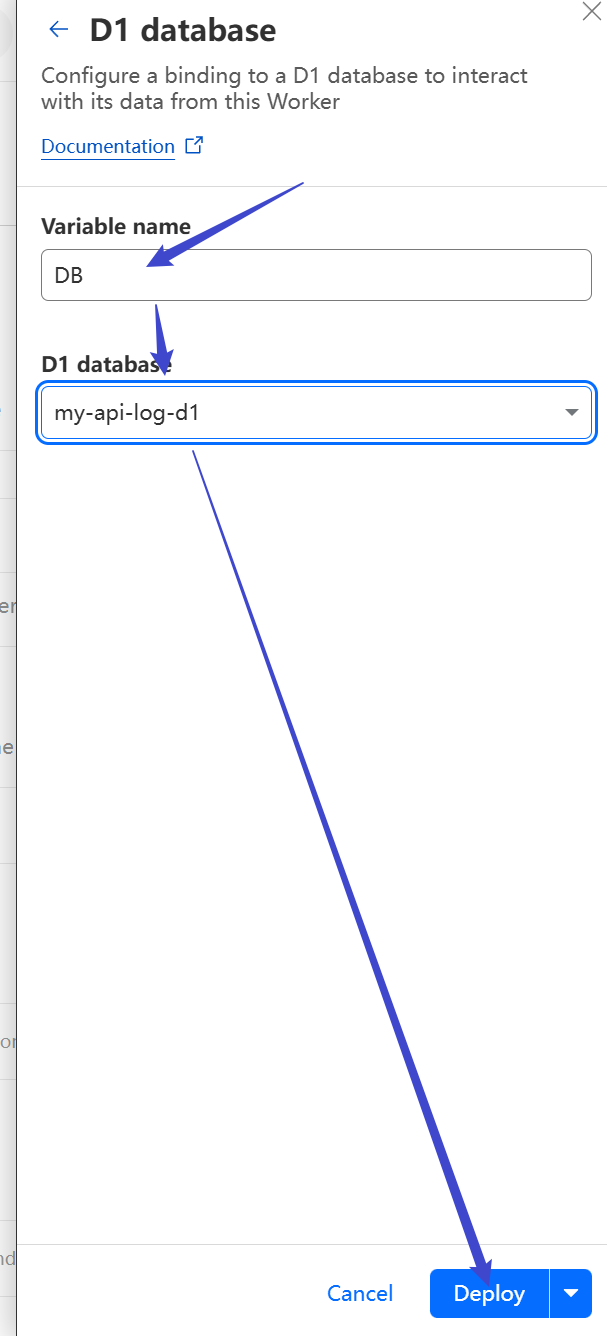
Set the variable name as `DB`, and choose the database you initialized. Click Deploy.
### Set Worker Environment Variables
By default, the Worker only forwards API requests and does nothing else. To enable additional features, set these environment variables:
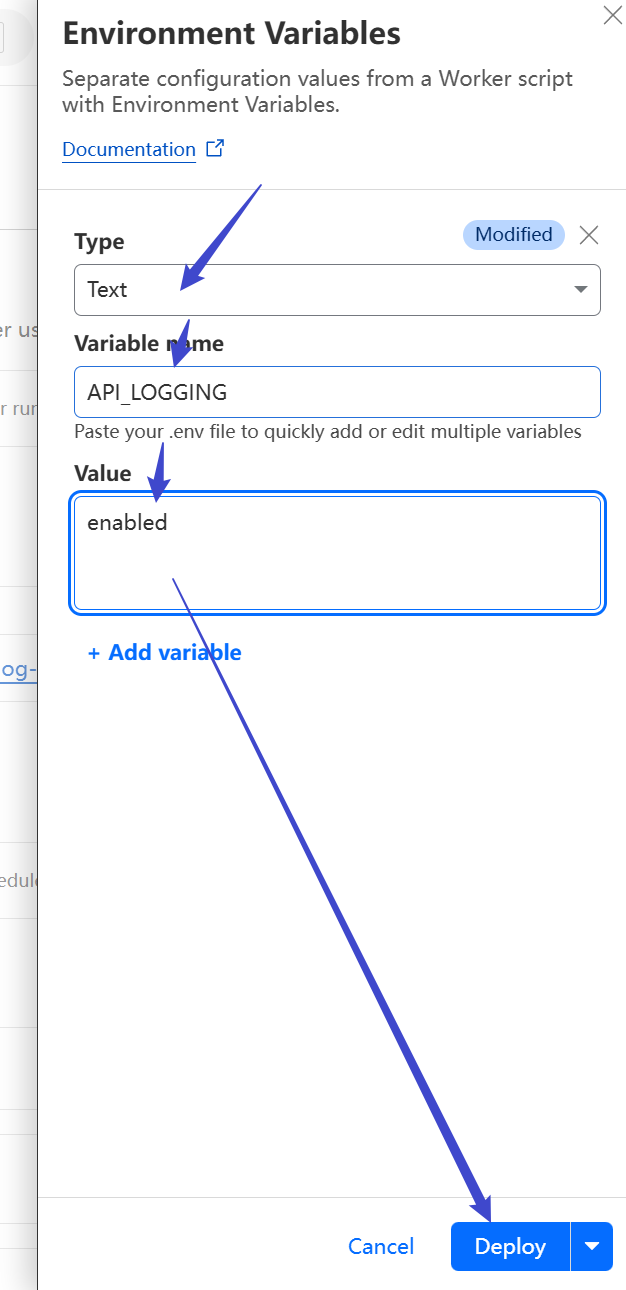
To enable logging:
* Add variable: `API_LOGGING`
* Value: `enabled`
To enable log download interface, set an API key:
* Variable: `API_SEC_KEY`
* Value: A secret key only you know
To enable model rewriting:
* Variable: `API_MODEL_REWRITE`
* Format: `model1=>model2,model3=>model4`
## Start Sending Requests
Assume your Worker endpoint is:
`wandering-poetry-3106.hash070.workers.dev`
To access OpenAI's Chat Completions API, send requests to:
`https://wandering-poetry-3106.hash070.workers.dev/v1/chat/completions`
To access the Messages API, use:
`https://wandering-poetry-3106.hash070.workers.dev/v1/messages`
To download logs:
Open this URL in a browser, replacing address and key with your own:
```
https://[your-worker-address]/logs?key=[your-API_SEC_KEY]&format=[format]
Example:
https://wandering-poetry-3106.hash070.workers.dev/logs?key=your-secret-key&format=csv
```
* `key` = your `API_SEC_KEY`
* `format` = `json` or `csv`
To clear logs:
Access this URL in your browser:
```
https://[your-worker-address]/clear-logs?key=[your-API_SEC_KEY]
```
Response:
```json
{"success":true,"message":{"en":"Logs cleared successfully","zh":"日志已成功清除"}}
```
***
### API Interface Summary
**Log Export**
```
Endpoint: /logs
Method: GET
Params:
key: API_SEC_KEY (required)
format: export format (optional, default csv)
- csv: CSV format
- json: JSON format
```
Example:
```
/logs?key=your-api-key
/logs?key=your-api-key&format=json
```
**Log Clearing**
```
Endpoint: /clear-logs
Method: GET
Params:
key: API_SEC_KEY (required)
```
Example:
```
/clear-logs?key=your-api-key
```
file: ./content/docs/orders/cloudflare-worker.mdx
meta: {
"title": "自建Cloudflare Worker反代",
"icon": "Cloud"
}
# 简介
本文主要说明如何自建一个基于Cloudflare Worker的API反代服务,实现API原始数据记录+自定义模型重写功能。
由于偶尔会有部分用户想自定义模型名称以便兼容某些行为奇怪的客户端,有些用户想要获得API交互的原始数据以排查错误,但是我们出于兼容性和保护客户隐私的方面考虑,不太愿意在服务端直接对这些功能添加支持,因此我们设计了一个基于CF Worker的小脚本简单实现这些功能的同时,兼顾安全性和隐私。
效果展示:
API模型重写`claude-3-haiku=>claude-3-5-haiku,claude-3.5-haiku-8080=>claude-3-5-sonnet`:

API交互原始数据记录:

# 配置
## 创建Worker
进入您的Cloudflare Dashboard控制面板
点击`Worker & Pages` => `Overveiw` => `Create` 创建新的Worker


名字随意,点击创建即可

## 编辑Worker代码
创建成功后点击编辑代码:

将原有代码清空,然后把下面整段代码全部复制进去,然后点击`Deploy`保存并更新部署
```javascript
/**
* API 代理与日志记录服务
*
* 环境变量配置:
* - API_LOGGING: 设置为 "enabled" 时启用日志记录
* - API_SEC_KEY: API Token,用于访问管理接口
* - API_MODEL_REWRITE: 模型重写规则,格式: "model1=>model2,model3=>model4"
*
* 数据库配置:
* - 需要在 Cloudflare D1 中创建数据库并绑定为 "DB"
*/
// 错误消息模板
const ERROR_MESSAGES = {
DB_NOT_CONFIGURED: {
en: "D1 database is not properly configured. Please check the documentation for setup instructions.",
zh: "D1 数据库未正确配置,请查阅文档进行配置。"
},
DB_TABLE_MISSING: {
en: "Required database table 'api_logs' is missing. Please create the table first.",
zh: "数据库表 'api_logs' 不存在,请先创建数据表。"
},
INVALID_MODEL_REWRITE: {
en: "Invalid model rewrite configuration. Format should be 'model1=>model2,model3=>model4'",
zh: "模型重写配置格式错误,正确格式应为:'model1=>model2,model3=>model4'"
}
};
// 创建错误响应
function createErrorResponse(errorKey) {
const error = ERROR_MESSAGES[errorKey];
return new Response(JSON.stringify({
error: {
en: error.en,
zh: error.zh
}
}), {
status: 500,
headers: { 'Content-Type': 'application/json' }
});
}
// 解析模型重写规则
function parseModelRewrites(rewriteConfig) {
if (!rewriteConfig) return null;
const rewrites = new Map();
try {
rewriteConfig.split(',').forEach(rule => {
const [from, to] = rule.trim().split('=>');
if (!from || !to) throw new Error('Invalid rule format');
rewrites.set(from.trim(), to.trim());
});
return rewrites;
} catch (error) {
throw new Error(ERROR_MESSAGES.INVALID_MODEL_REWRITE.en);
}
}
export default {
async fetch(request, env) {
const url = new URL(request.url);
// 处理管理接口
if (url.pathname === '/logs' || url.pathname === '/clear-logs') {
return await handleAdminRequest(request, env, url);
}
// API 反向代理
if (url.pathname.startsWith('/v1')) {
return await handleProxyRequest(request, env, url);
}
return new Response('Not Found', { status: 404 });
}
};
async function handleProxyRequest(request, env, url) {
// 克隆请求信息,用于记录和模型重写
const timestamp = new Date().toISOString();
const requestHeaders = Object.fromEntries([...request.headers]);
let requestBody = '';
let modifiedRequest = request;
// 处理请求体和模型重写
if (request.method === 'POST' && request.body) {
const clonedRequest = request.clone();
requestBody = await clonedRequest.text();
// 模型重写处理
if (env.API_MODEL_REWRITE) {
try {
const bodyJson = JSON.parse(requestBody);
const rewrites = parseModelRewrites(env.API_MODEL_REWRITE);
if (bodyJson.model && rewrites?.has(bodyJson.model)) {
const newModel = rewrites.get(bodyJson.model);
bodyJson.model = newModel;
requestHeaders['x-model-rewrite'] = `${bodyJson.model}=>${newModel}`;
requestBody = JSON.stringify(bodyJson);
// 创建新的请求对象
modifiedRequest = new Request(request.url, {
method: request.method,
headers: request.headers,
body: requestBody
});
}
} catch (error) {
return createErrorResponse('INVALID_MODEL_REWRITE');
}
}
}
// 执行反向代理请求
url.host = 'api.ohmygpt.com';
const response = await fetch(url, {
method: modifiedRequest.method,
headers: modifiedRequest.headers,
body: modifiedRequest.body
});
// 如果启用了日志记录,则记录请求和响应
if (env.API_LOGGING === 'enabled') {
if (!env.DB) {
console.error('Database not configured but logging is enabled');
return createErrorResponse('DB_NOT_CONFIGURED');
}
try {
const clonedResponse = response.clone();
const responseBody = await clonedResponse.text();
const responseHeaders = JSON.stringify(Object.fromEntries([...response.headers]));
await env.DB.prepare(`
INSERT INTO api_logs (
timestamp, request_path, request_method, request_headers,
request_body, response_status, response_headers, response_body
) VALUES (?, ?, ?, ?, ?, ?, ?, ?)
`).bind(
timestamp,
url.pathname,
request.method,
JSON.stringify(requestHeaders),
requestBody,
response.status,
responseHeaders,
responseBody
).run();
} catch (error) {
console.error('Failed to log request:', error);
return createErrorResponse('DB_TABLE_MISSING');
}
}
return response;
}
async function handleAdminRequest(request, env, url) {
const key = url.searchParams.get('key');
// 验证 API Token
if (!env.API_SEC_KEY || key !== env.API_SEC_KEY) {
return new Response('Unauthorized', { status: 401 });
}
// 检查数据库配置
if (!env.DB) {
return createErrorResponse('DB_NOT_CONFIGURED');
}
// 处理清理请求
if (url.pathname === '/clear-logs') {
try {
await env.DB.prepare('DELETE FROM api_logs').run();
return new Response(JSON.stringify({
success: true,
message: {
en: "Logs cleared successfully",
zh: "日志已成功清除"
}
}), {
headers: { 'Content-Type': 'application/json' }
});
} catch (error) {
return createErrorResponse('DB_TABLE_MISSING');
}
}
// 处理日志导出
try {
const { results } = await env.DB.prepare(
'SELECT * FROM api_logs ORDER BY timestamp DESC'
).all();
const format = url.searchParams.get('format') || 'csv';
if (format === 'json') {
return new Response(JSON.stringify(results, null, 2), {
headers: { 'Content-Type': 'application/json' }
});
}
// 默认导出 CSV
const csv = [
['Timestamp', 'Path', 'Method', 'Request Headers', 'Request Body',
'Response Status', 'Response Headers', 'Response Body'].join(',')
];
for (const row of results) {
csv.push([
row.timestamp,
row.request_path,
row.request_method,
`"${row.request_headers.replace(/"/g, '""')}"`,
`"${row.request_body.replace(/"/g, '""')}"`,
row.response_status,
`"${row.response_headers.replace(/"/g, '""')}"`,
`"${row.response_body.replace(/"/g, '""')}"`
].join(','));
}
return new Response(csv.join('\n'), {
headers: {
'Content-Type': 'text/csv',
'Content-Disposition': 'attachment; filename=api_logs.csv'
}
});
} catch (error) {
return createErrorResponse('DB_TABLE_MISSING');
}
}
```

## 创建并初始化D1数据库
`Worker & Pages` => `D1` => `Create`按钮创建新的数据库

名称随意,输入完后点击创建即可

初始化数据库,执行建表语句:
```
CREATE TABLE IF NOT EXISTS api_logs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT,
request_path TEXT,
request_method TEXT,
request_headers TEXT,
request_body TEXT,
response_status INTEGER,
response_headers TEXT,
response_body TEXT,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
```
将上面这段SQL复制到蓝框中执行

这样就算成功:

## 配置Worker
### 绑定D1数据库
找到刚刚创建的Worker

绑定D1数据库:


变量名这里填写`DB`,数据库就选择刚刚初始化的那个,点击Deploy部署即可

### 配置Worker环境变量
默认情况下,此时此Worker已经可以转发API了,但是不会进行任何行为
可以在这里设置Worker的环境变量


如果需要启用日志记录:
新增环境变量: `API_LOGGING`
将其设置为 `enabled`
如果需要使用日志下载接口,需要配置API密钥:
环境变量: `API_SEC_KEY`
设置为一个只有您知道的私密密钥
如果您需要模型重写功能:
设置环境变量: `API_MODEL_REWRITE`
格式: `model1=>model2,model3=>model4`
## 开始请求
假设您的Worker地址是:
`wandering-poetry-3106.hash070.workers.dev`
那么您如果想要访问OpenAI的Chat.Completions API接口,可以对这个接口发起请求 `https://wandering-poetry-3106.hash070.workers.dev/v1/chat/completions` , 如果想要访问Messages API接口,可以对 `https://wandering-poetry-3106.hash070.workers.dev/v1/messages` 发起请求

如果您需要下载日志:
可以在浏览器中打开形如下面这个URL(注意地址和Key按照这个格式替换成你自己搭建的
```
https://[你的Worker地址]/logs?key=[你的API_SEC_KEY]&format=[导出数据格式]
例如:
https://wandering-poetry-3106.hash070.workers.dev/logs?key=your-secret-key&format=csv
```
其中URL中的这个key参数应当填写为您设置的API\_SEC\_KEY变量,format指导出数据格式,可以是`json`或`csv`表格
如果您需要清除数据:
可以在浏览器中直接访问这个URL
```
https://[你的Worker地址]/clear-logs?key=[你的API_SEC_KEY]
```
```json
{"success":true,"message":{"en":"Logs cleared successfully","zh":"日志已成功清除"}}
```
附:
API 接口说明
日志导出
```
地址:/logs
方法:GET
参数:
key:API_SEC_KEY(必填)
format:导出格式(可选,默认 csv)
csv:CSV 格式
json:JSON 格式
```
示例:
```
/logs?key=your-api-key
/logs?key=your-api-key&format=json
```
日志清理
```
地址:/clear-logs
方法:GET
参数:
key:API_SEC_KEY(必填)
```
示例:
```
/clear-logs?key=your-api-key
```
file: ./content/docs/orders/ivs.en.mdx
meta: {
"title": "Self-Service Invoicing System",
"description": "User Guide for the Self-Service Invoicing System",
"icon": "TicketCheck"
}
# Introduction
To better support Chinese mainland enterprise/institution clients with electronic invoicing, we launched a self-service invoicing system on October 17, 2024. This system is owned and operated by the mainland entity "Longgang Xianda Technology Co., Ltd."
Website: [https://ivs.dogenet.cn](https://ivs.dogenet.cn)
With this system, you can:
* Apply for mainland China B2B electronic invoices by yourself
* Download issued electronic invoices
* Submit mainland China B2B bank transfer top-up requests
# How to Use
## 1. Create or Log in to Your Account
When you first enter the system, you will be asked to log in or register a self-service invoicing system account.
**Note: This account is independent of your OhMyGPT account. The invoicing system accesses your OhMyGPT order data via OAuth open interface.**
## 2. Complete OAuth Authorization
To allow the system to access your OhMyGPT order information, you need to authorize this application to access your OhMyGPT account:
After clicking authorize, you will be redirected back to the self-service invoicing system:
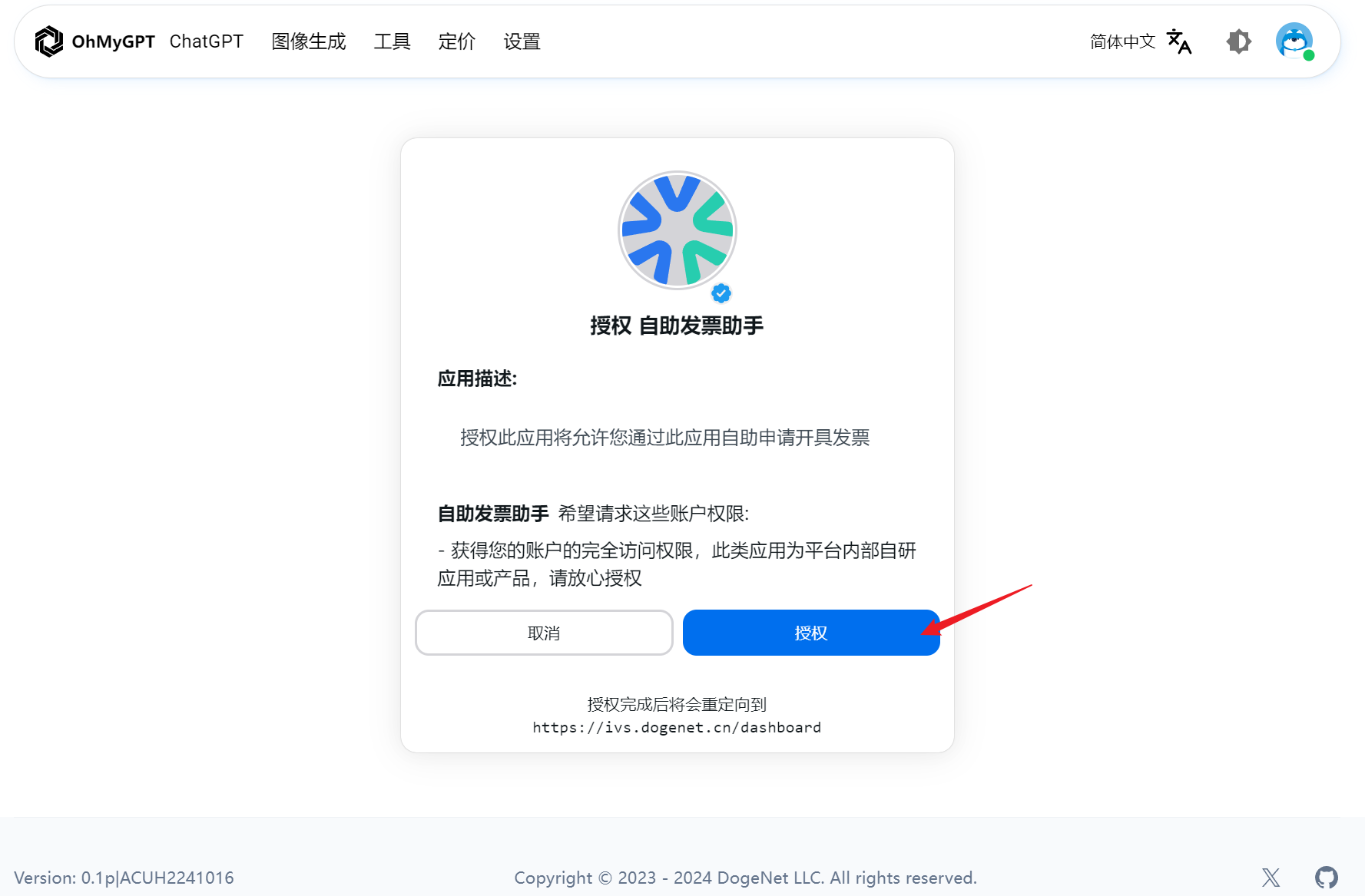
Once authorization is successful, you'll see your invoicing dashboard:
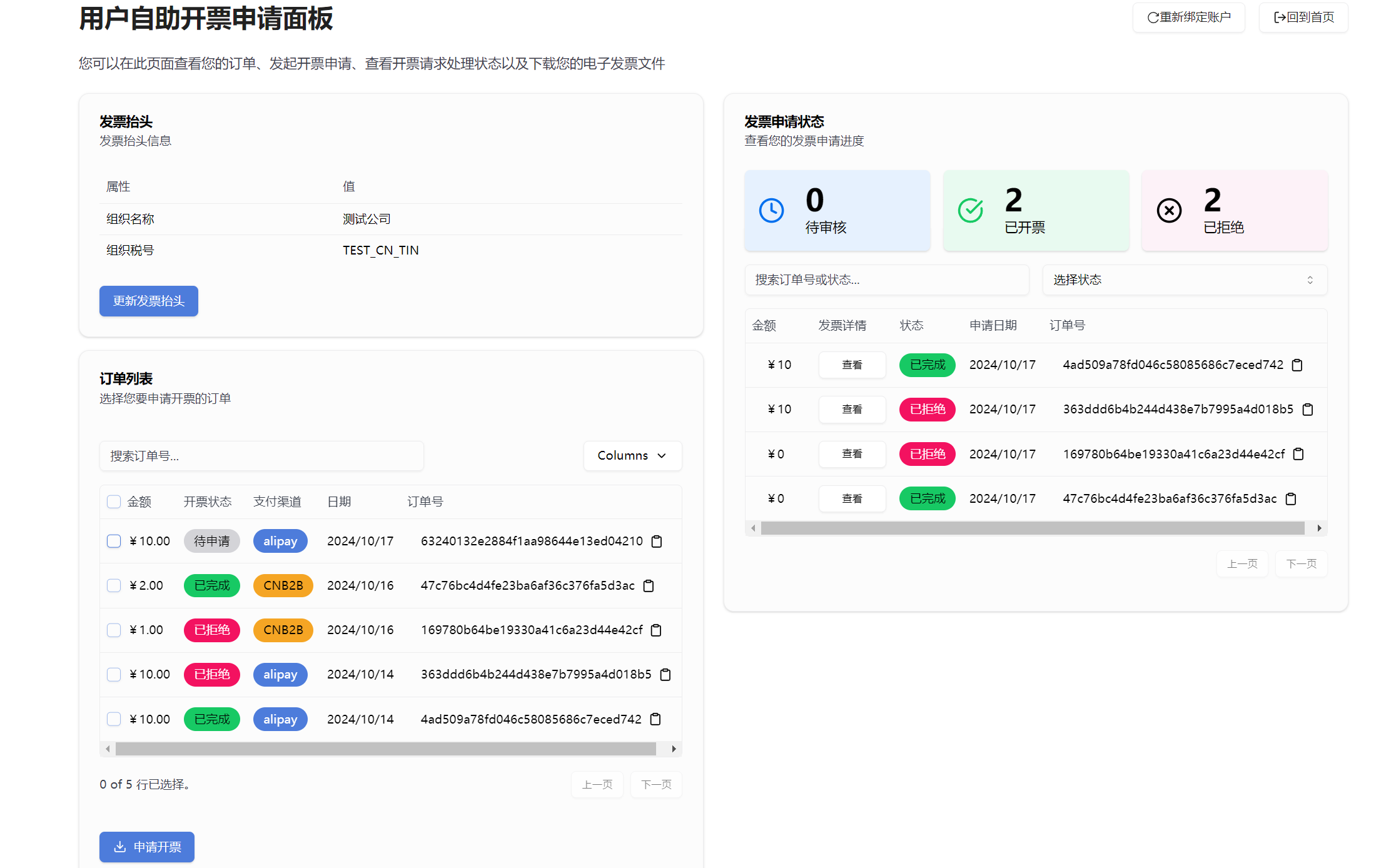
## 3. Fill In Invoice Header Information
To issue an electronic invoice in mainland China, you must provide at least the following information:
* Organization Name
* Taxpayer Identification Number (TIN)
Other fields are optional.
If you provide bank name and bank account information, these will appear in the invoice remarks.
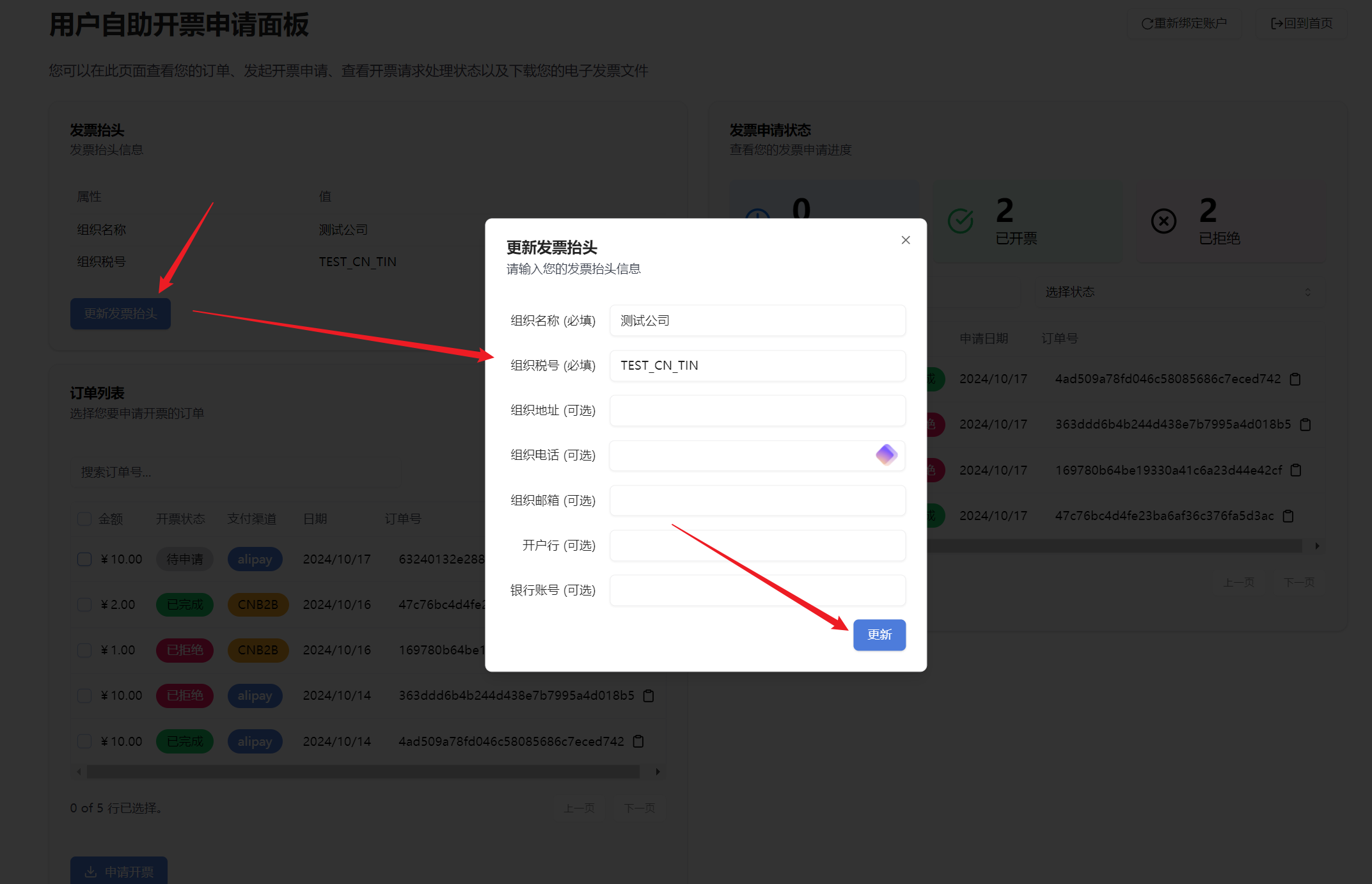
**Note: Chinese invoices are connected to the tax authority's system. Please ensure that all tax information is entered accurately. If you provide incorrect tax details and an incorrect invoice is issued, you may be held legally and financially responsible.**
## 4. Apply for Invoicing
You can select orders marked as “Pending Application” and then click the “Apply for Invoice” button below.
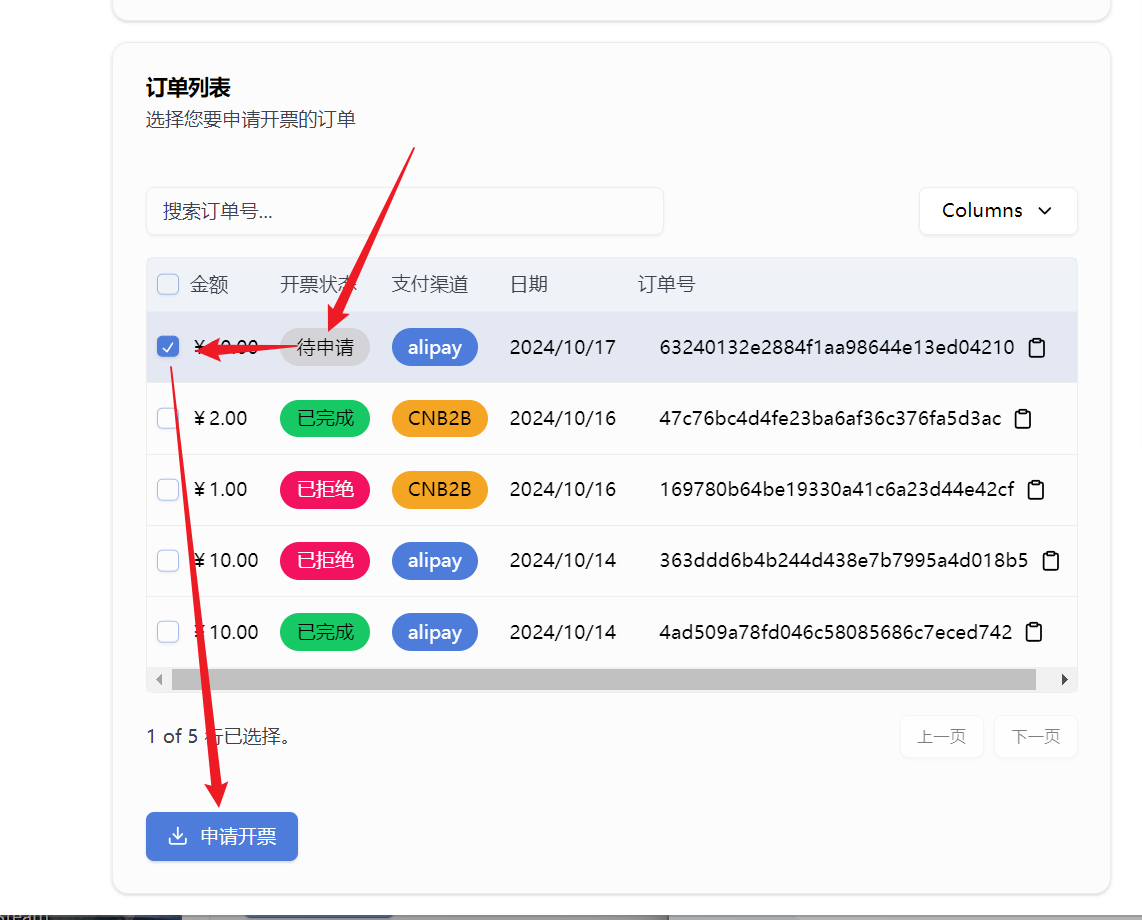
After submission, our accountant will be notified and will process your request. You will be notified once it’s complete.
**Note: Do not submit duplicate applications. This system only shows orders that meet specific criteria. If you don’t see your order, it’s usually not a bug, but means the order needs manual review. In such cases, please contact customer service via email: [help@ohmygpt.com](mailto:help@ohmygpt.com)**
## 5. Download the Invoice
Once the invoice is issued, click the “View” button. In the pop-up window, click “Download Invoice” to get the invoice file.
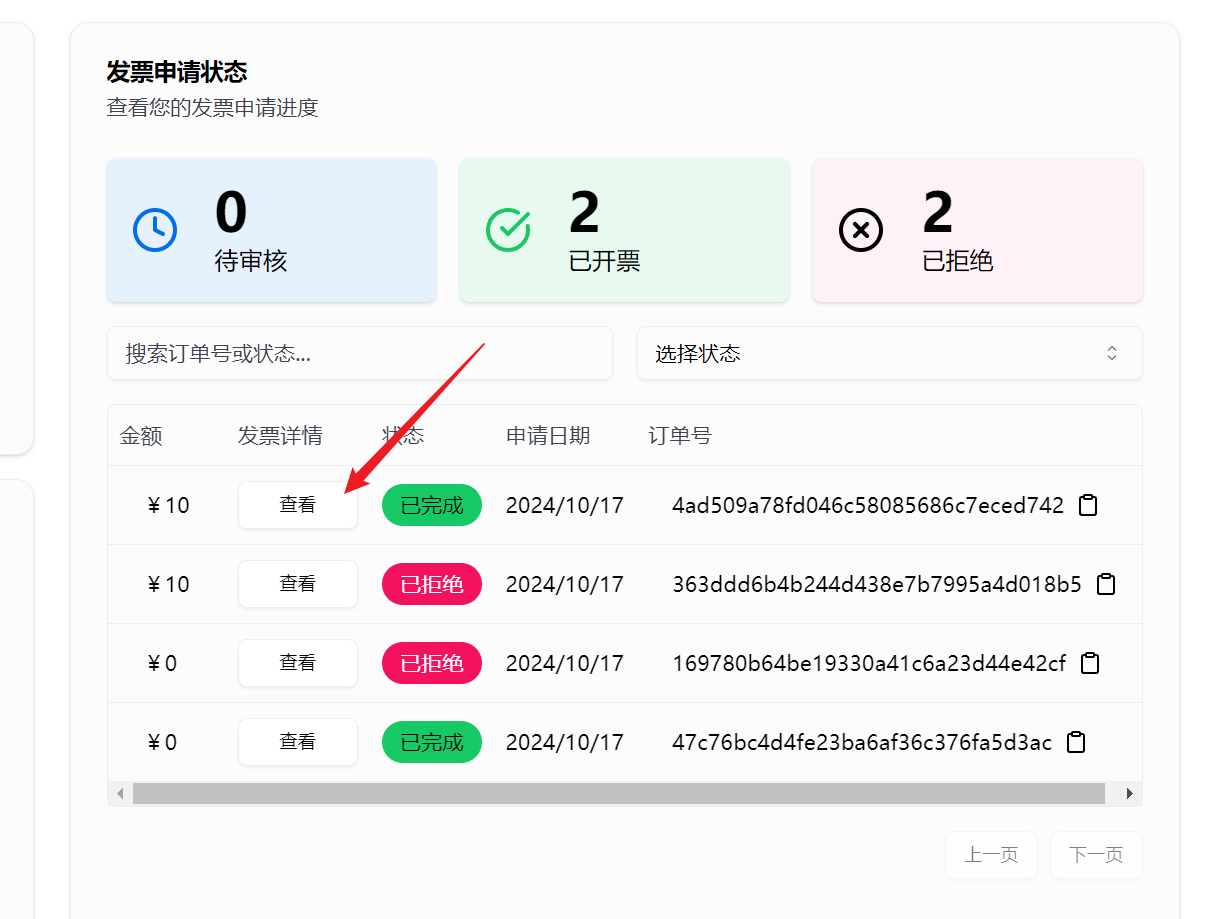
# Mainland B2B Bank Transfer
On the user page, click the “Apply for B2B Transfer Top-Up” card to view the company’s bank account information. Complete the B2B payment based on the provided info, fill out the form, and upload proof. After verification, our admin will complete your top-up request.
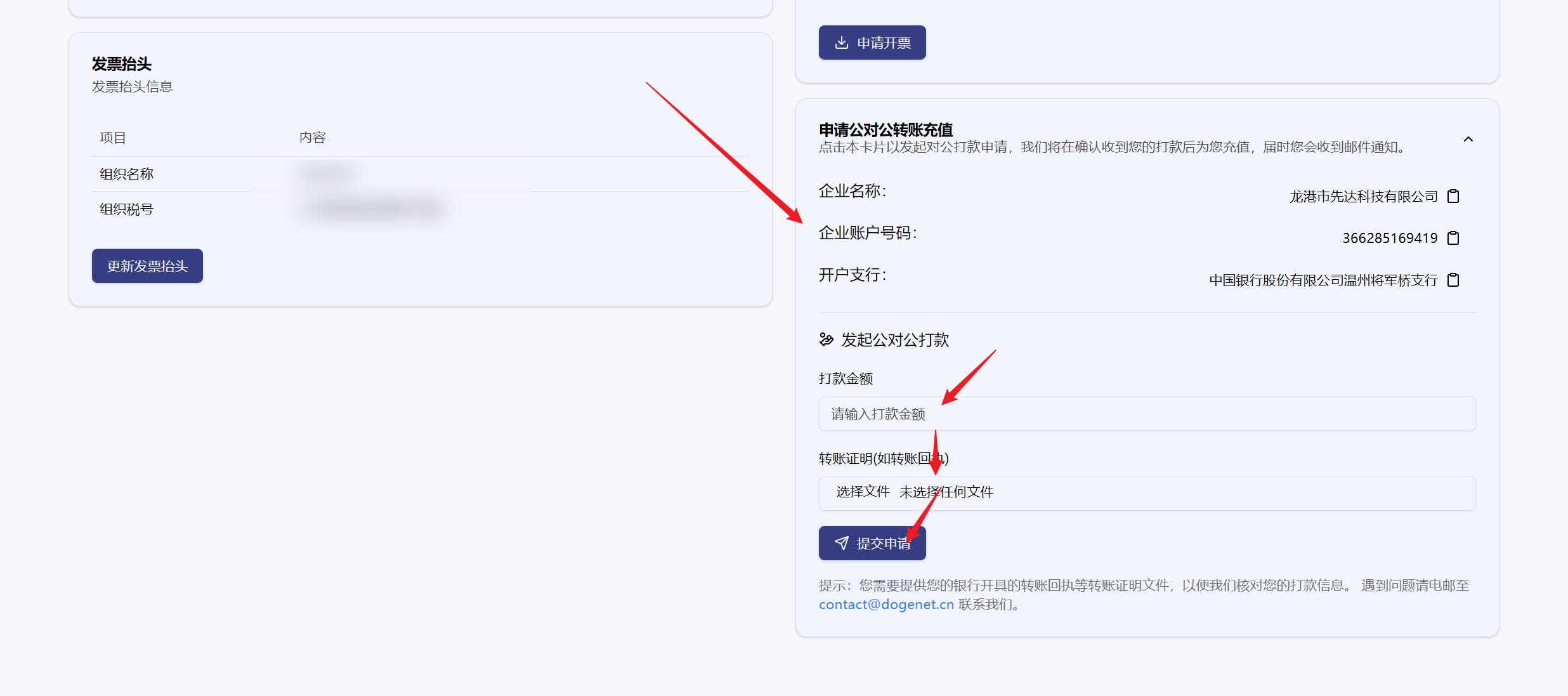
# Additional Information
## About Quotes / Contracts
If your organization requires a quotation or contract, we can issue PDF files with electronic seals and digital signatures. Please contact customer service via email for details.
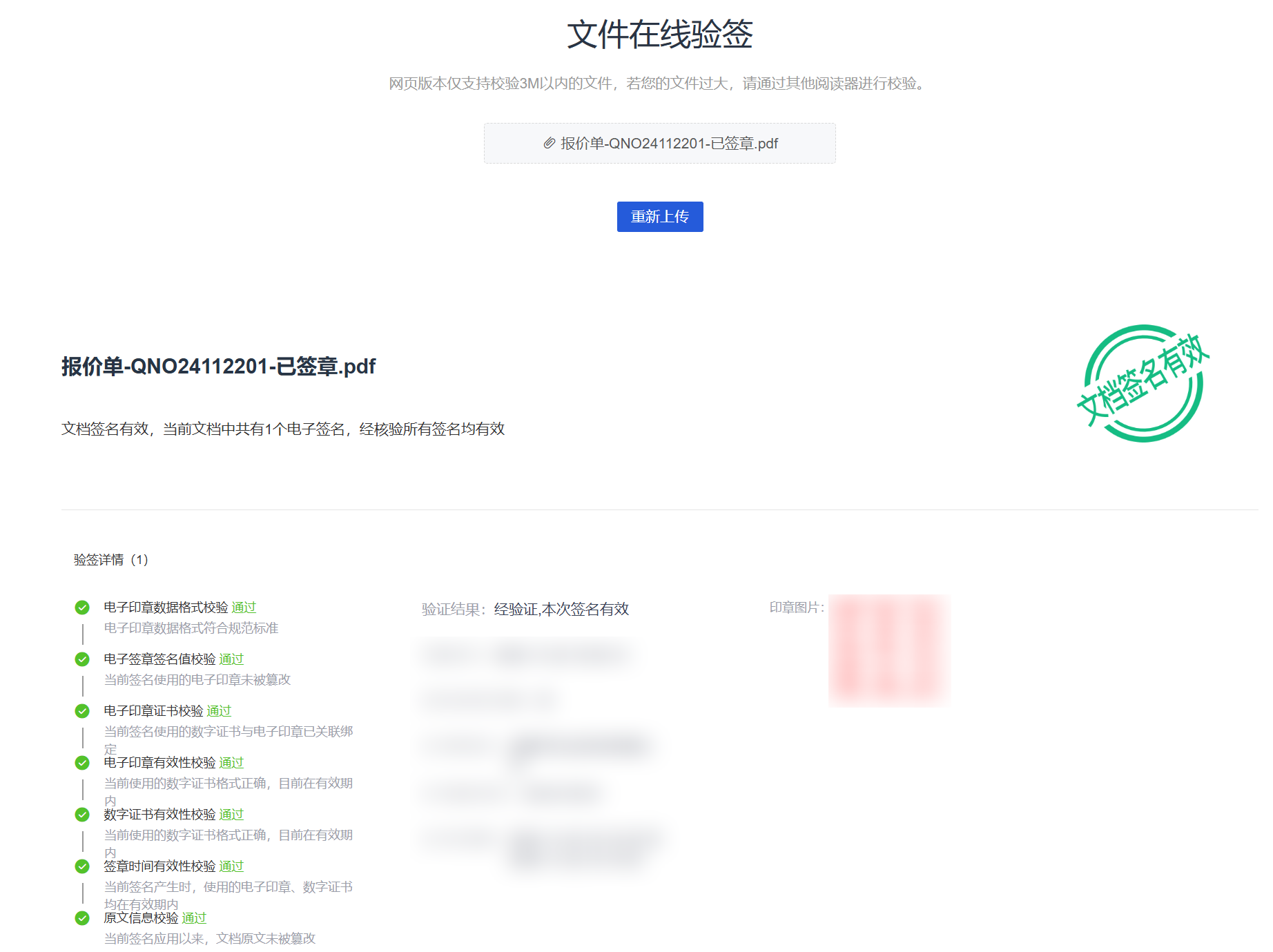
## About the Next Site Mirror
`https://next.aigptx.top` is a mirror site for our new version. You can log in using email + password and complete OAuth authorization there.
If you need to change your OhMyGPT account email, you can also do it via the settings page on the new site:
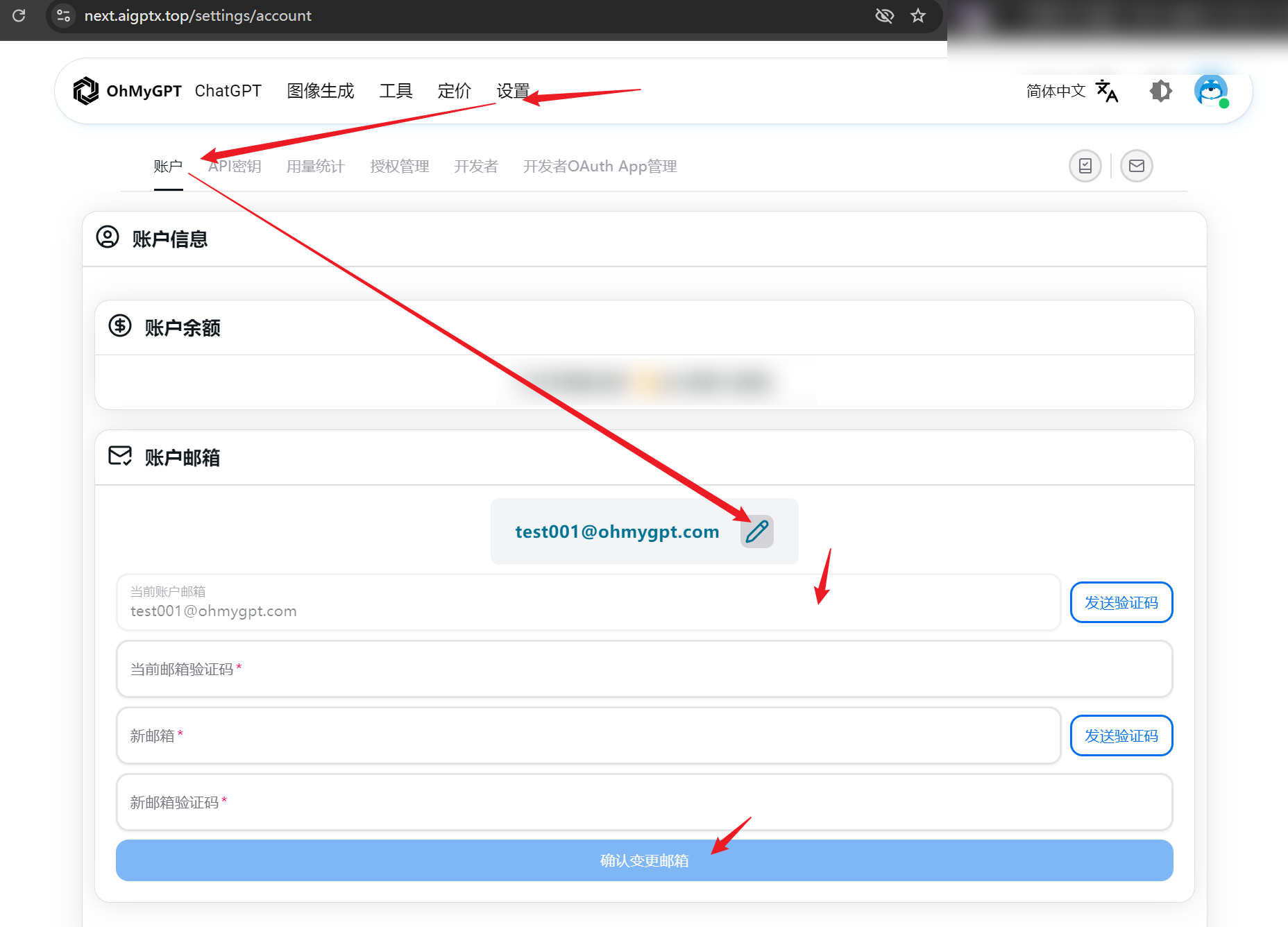
file: ./content/docs/orders/ivs.mdx
meta: {
"title": "自助开票系统",
"description": "自助开票系统使用教程",
"icon": "TicketCheck"
}
# 简介
为了方便大陆的企业/机构客户的电子发票开票需求,我们于24-1017上线了自助开票系统,此系统由大陆主体“龙港市先达科技有限公司”持有和运营。
网站地址: [https://ivs.dogenet.cn](https://ivs.dogenet.cn)
您可以通过此系统完成:
* 自助申请开具大陆公对公电子发票
* 自助下载已开具的电子发票
* 自助申请大陆公对公转账充值
# 使用方法
## 1 创建或登入您的账号
在首次进入系统时,您会被要求登录/注册一个自助发票系统的账号
**注意:此系统的账号和OhMyGPT的账号相互独立,系统通过OAuth开放接口访问您的OhMyGPT账号的订单数据。**
## 2 完成OAuth授权
为了让此系统访问您的OhMyGPT账号的订单信息,您需要授权此应用访问您的OhMyGPT账号:

点击授权后,即可跳转回自助开票系统:

授权成功后,您可以看到您的自助开票面板:

## 3 填写发票抬头
要在中国大陆开具一张电子发票,您至少需要提供如下信息:
* 组织名称
* 组织税号
其它信息选填
其中如果您填写了的话开户行和银行账号这两项,它们会展示在发票备注中。

**注意:中国大陆的发票是接入zf税务系统的,请务必确保您的税务信息填写正确,如因您填写了错误的税务信息导致开出了错误的发票,您将可能承担相应的税务/法律责任。**
## 4 申请开票
您可以勾选“待申请”状态的订单,然后点击下方的“申请开票”按钮

点击完成后,会计将会收到通知并处理您的开票请求,在处理完成后您会收到相应的通知。
**注意:请勿重复提交开票申请,此系统只会展示符合特定条件的订单,如果您没有在此系统中看到您的订单,这通常不是Bug,而是表示该订单需要管理员复核,这种情况下请通过邮件联系客服: [help@ohmygpt.com](mailto:help@ohmygpt.com)**
## 5 下载发票
当发票完成开具后,点击“查看”按钮,在弹窗中点击“下载发票”,您即可获得发票文件。

# 大陆公对公转账
在用户页面中,点击“申请公对公转账充值”卡片,即可看到公司银行账户信息,您根据此信息完成对公付款后,填写此表单,同时提交证明文件,我们的管理员会在核实后完成您的充值订单。

# 其它说明
## 关于报价单/合同等
如果您的组织需要报价单/合同等文件,我们可以为您开具带电子印章+数字签名的PDF文件,具体请通过邮件联系客服

## 关于Next站的镜像
`https://next.aigptx.top` 是本站的新版网站的镜像站,您可以在此站通过邮箱+密码登录完成OAuth授权
如果您需要换绑您的OhMyGPT账户邮箱,您也可以在新版网站的设置中进行自助换绑:

file: ./content/docs/overview/about.en.mdx
meta: {
"title": "About OhMyGPT",
"description": "Leading AI technology, accessible for everyone.",
"icon": "Info"
}
Welcome to OhMyGPT! We're committed to bringing cutting-edge AI technology to everyone, making advanced tech accessible to all users.
## Our Mission
At OhMyGPT, our mission is to break down technological and regional barriers to provide stable, reliable, and advanced AI services to users across the globe. We firmly believe that technological equality can drive the world toward a better future.
## Our Unique Advantages
* **Established Platform:** Launched in March 2023, OhMyGPT has been running stably ever since. As an early entrant in the AI space, we've built extensive experience, industry connections, and a strong user base. We've also signed service-level or discounted contracts with leading AI and tech companies in both the US and China.
* **Secure and Reliable:** Your data privacy and security are paramount. We use industry-leading cybersecurity standards and technologies, deploy high-performance computing clusters in a distributed manner, encrypt all communications with TLS, and ensure no unauthorized logging of your data.
* **Flexible and User-Friendly:** Say goodbye to complicated plans, quotas, and regional restrictions. We offer a simple **Pay-as-you-go** pricing model, support multiple payment methods, and offer automatic billing, giving you maximum flexibility based on your needs.
* **All-in-One Service:** We support leading AI models including (but not limited to) OpenAI, Claude, and Gemini. Most models provide OpenAI-compatible API interfaces, with efficient API key management and usage analytics—ideal for developers.
* **No Account Ban Worries:** Unlike using services from OpenAI or Anthropic directly, OhMyGPT users don't have to worry about payment issues, regional restrictions, arbitrary bans, financial losses, or legal and tax compliance risks.
* **Compliant and Stable:** OhMyGPT is legally operated by **DogeNet LLC** in the United States, and serves users through its localized branches in China and Japan.
* **Tax Compliance:** We support international invoices and Chinese e-invoices, and will soon offer compliant receipts for Japan. Whether you're part of a company or organization anywhere in the world, we help you stay tax-compliant.
## Our Commitment and Vision
We're continually exploring the potential of AI, aiming to develop more practical and innovative use cases. We value every user's feedback—your support drives us to keep improving.
* **Official Site (New):** [next.ohmygpt.com](https://next.ohmygpt.com)
* **Official Site (Legacy):** [www.ohmygpt.com](https://www.ohmygpt.com)
* **Mirror Sites (New):**
* [next.aigptx.top](https://next.aigptx.top)
* **Mirror Sites (Legacy):**
* [x.dogenet.win](https://x.dogenet.win)
* [www.aigptx.top](https://www.aigptx.top)
* **Official Telegram Group:** [t.me/+SfPmr1psSNNhMzg1](https://t.me/+SfPmr1psSNNhMzg1)
* **Service Status Pages:**
* [status.ohmygpt.com/status/main](https://status.ohmygpt.com/status/main)
* [status.aigptx.top/status/main](https://status.aigptx.top/status/main)
***
## Rate Limits
To ensure fair API usage and prevent abuse, we assign different rate limits based on user tier, which is automatically determined by your cumulative recharge amount.
| Membership Tier | Cumulative Recharge | API Limit (req/min) | Key Features / Target Users |
| :-------------- | :------------------ | :------------------ | :------------------------------------------------ |
| Free | ¥0+ | 60 | Basic functionality for free trial users |
| VIP | ¥20+ | 1200 | Higher rate for individuals or small teams |
| Premium | ¥300+ | 10000 | High-rate API, priority support, enterprise-grade |
***
## API Services
We offer OpenAI-compatible APIs supporting `Audio`, `Chat`, `Completions`, `Embeddings`, `Images`, and `Moderations`. Developers only need to change the base API URL from `https://api.openai.com` to one of the endpoints below.
**API Endpoint List:**
| Endpoint URL | Features | Recommended Use Case |
| :-------------------------------- | :------------------------------------------------------- | :------------------------- |
| `https://api.ohmygpt.com` | Direct US server access, stable | Users located in the US |
| `https://apic.ohmygpt.com` | Cloudflare CDN (Pro), global acceleration (100s timeout) | Users outside the US |
| `https://c-z0-api-01.hash070.com` | Mainland China optimized CDN (100s timeout) | Mainland China users |
| `https://cn2us02.opapi.win` | High-quality CN2 GIA route proxy (no timeout limit) | General use, backup option |
**Usage Tips:**
* **Location:** US-based users should prefer the direct endpoint; users in Asia or other regions farther from the US are advised to use CDN or proxy endpoints.
* **Request Type:**
* **Non-streaming requests:** Use direct or proxy endpoints (wider timeout windows).
* **Streaming requests:** CDN endpoints are usually not affected by Cloudflare's 100s timeout limit.
file: ./content/docs/overview/about.mdx
meta: {
"title": "关于 OhMyGPT",
"description": "领先的人工智能技术,为每一个人。",
"icon": "Info"
}
欢迎使用 OhMyGPT!我们致力于将尖端的人工智能技术带给每一位用户,让先进技术触手可及。
## 我们的使命
在 OhMyGPT,我们的使命是打破技术壁垒以及封锁,尽可能向世界绝大多数地区的用户提供稳定、放心、可靠以及先进的人工智能服务,我们坚信科技平权更能带动和推进世界向更美好的方向的发展。
## 我们的独特优势
* **老牌站点:** 本站于2023年3月上线开始运营,一直稳定运营至今,我们在行业早期入局,积累了大量的人脉、维护经验以及用户,同时与美国和中国的知名人工智能和科技公司有签署服务等级或低价合同,老牌站点,放心可靠。
* **安全可靠:** 您的数据安全与隐私至关重要。我们采用行业领先的网络安全标准和技术,分布式部署了高性能计算集群,全程通信采用TLS加密,同时保证不会在未经授权的情况下记录您的通信数据,确保在处理您的请求时尽可能保证高并发、安全与稳定。
* **灵活自由:** 告别复杂的套餐和使用限额以及区域限制。我们提供简单的\*\*随用随付(Pay-as-you-go)\*\*的计费模式,支持多种支付方式,也提供绑卡自动扣款功能,让您根据您的实际需求灵活高效地使用本站的服务。
* **一站服务:** 本站支持时下流行且先进的 AI 模型,包括但不限于OpenAI、Claude以及Gemini,并且大部分模型提供 OpenAI 标准的兼容开放 API 接口,提供高效的APIKey管理以及用量分析功能,方便开发者集成。
* **无惧封号:** 相比于直接使用OpenAI、Anthropic等厂商的AI服务,在本站使用同样的服务,不用再担心付款困难、地区限制、莫名其妙的封号或者承担封号带来的直接和间接经济损失,以及法律和税务合规等风险。
* **合规稳定:** OhMyGPT 目前主要由 **DogeNet LLC** 在美合法合规运营,同时通过中国和日本的分公司以本土化的形式对接客户。
* **税务合规:** 我们支持开具国际标准的Invoice,支持开具大陆电子发票,也即将支持开具日本本土的适格请求书,无论您的公司或组织在世界各地,都可以轻松帮助您完成税务合规,确保完成进项抵扣以及报销合规。
## 我们的承诺与展望
我们持续探索 AI 的潜力,致力于开发更多实用、创新的应用场景。我们珍视每一位用户的反馈,您的支持是我们不断前进、优化服务的动力。
* **官网(新版网站):** [next.ohmygpt.com](https://next.ohmygpt.com)
* **官网(旧版网站):** [www.ohmygpt.com](https://www.ohmygpt.com)
* **镜像站(新版)(访问主域名困难时可尝试):**
* [next.aigptx.top](https://next.aigptx.top)
* **镜像站(旧版)(访问主域名困难时可尝试):**
* [x.dogenet.win](https://x.dogenet.win)
* [www.aigptx.top](https://www.aigptx.top)
* **官方 Telegram 群组:** [t.me/+SfPmr1psSNNhMzg1](https://t.me/+SfPmr1psSNNhMzg1) (获取最新通知)
* **服务状态页面:**
* [status.ohmygpt.com/status/main](https://status.ohmygpt.com/status/main)
* [status.aigptx.top/status/main](https://status.aigptx.top/status/main)
***
## 速率限制
为了确保API配额的公平分配,避免潜在的滥用或破坏,我们通过检查用户的累计充值记录以识别用户等级,从而应用不同的速率限制。
本站分为三个会员等级:`Free`, `VIP`, `Premium`,系统会根据您的充值记录自动给您分配和应用对应的等级和速率限制。
| 会员等级 | 累计充值 | API 限制 (次/分钟) | 核心优势/适合用户 |
| :------ | :---- | :------------ | :--------------------- |
| Free | ¥0+ | 60 | 免费体验,基础功能,尝鲜用户 |
| VIP | ¥20+ | 1200 | 提升API速率,适用于个人/小型团队 |
| Premium | ¥300+ | 10000 | 高速率API,提供优先支持,高需求/企业用户 |
***
## API 服务
本站提供与 OpenAI 官方 API 兼容的接口,支持 `Audio`, `Chat`, `Completions`, `Embeddings`, `Images`, `Moderations` 等功能。开发者只需将 API 请求的基础 URL 从 `https://api.openai.com` 替换为本站提供的以下任一 API 端点即可。
**API 端点列表:**
| 端点 URL | 特点 | 推荐使用场景 |
| :-------------------------------- | :----------------------------------------------- | :------- |
| `https://api.ohmygpt.com` | 美国主站直连,稳定直连 | 美国本土调用 |
| `https://apic.ohmygpt.com` | Cloudflare CDN (Pro),稳定,全球加速 (HTTP请求有100s超时限制) | 非美国地区调用 |
| `https://c-z0-api-01.hash070.com` | 大陆优化 CDN,大陆优化 (HTTP请求有100s超时限制) | 中国大陆地区调用 |
| `https://cn2us02.opapi.win` | 大陆优化优质线路(CN2 GIA)反代 (HTTP请求无超时限制) | 通用,备选 |
**使用建议:**
* **地理位置:** 美国用户推荐直连端点;亚洲等距离美国较远地区推荐使用 CDN 或反代端点。
* **请求类型:**
* **非流式请求:** 推荐使用直连或反代端点(超时限制更宽松)。
* **流式请求:** 可以使用 CDN 端点(通常不受 Cloudflare 100 秒超时限制)。
file: ./content/docs/overview/faq.en.mdx
meta: {
"title": "FAQ",
"description": "Frequently Asked Questions about OhMyGPT",
"icon": "CircleHelp"
}
## Getting Started
OhMyGPT provides a unified API that gives you access to major AI models on the market, including but not limited to
OpenAI, Claude, and Gemini. You can manage billing in one place and track all usage with our analytics tools.
```
We ensure service stability and reliability, so you don’t have to worry about payment issues, regional restrictions,
or account bans. As a well-established provider since March 2023, we have extensive operational experience and a
strong user base.
```
First, create an account and add credit on the [Billing](https://next.ohmygpt.com/billing) page. We use a simple
**Pay-as-you-go** model that allows you to flexibly use the service based on actual needs.
```
When you use the API or chat interface, the cost of the request is deducted from your credit balance. Each model has
different pricing, which you can view on the model page.
```
The best way to get support is by joining our [official Telegram group](https://t.me/+SfPmr1psSNNhMzg1) for the
latest updates and assistance.
```
You can also contact our support team through:
- Email: support@ohmygpt.com
- Live Chat: via the bottom-right corner of our website
```
We display clear pricing for each model. Depending on the model, pricing may be based on token count, request count,
or other units.
```
We offer a straightforward **Pay-as-you-go** billing model so you can pay based on actual usage, with no complex
plans or usage limits.
You can view your full usage history and spending records in the user dashboard to help track and manage your
expenses.
**Billing Method and Principle:**
For common large language model interfaces such as GPT, Claude, and Gemini, we generally do not parse or calculate
token usage directly due to complexity and accuracy. Instead, we bill based on the `usage` field returned by the
API, multiplied by a markup rate. For example, if a request costs $10 based on the official price and the markup is
1.1, you will be charged $11 in credit.
```
## Models and Providers
OhMyGPT provides access to a wide variety of large language models from leading AI labs. You can browse the full
list on our [model browser](https://next.ohmygpt.com/pricing).
We add new models as quickly as possible. Our close collaboration with major AI providers allows us to rapidly
integrate new releases into our platform.
If you would like us to support a specific model, please contact us via [Telegram](https://t.me/+SfPmr1psSNNhMzg1)
or our support channels.
We adopt industry-leading security standards and technologies, with distributed high-performance compute clusters.
All communication is encrypted with TLS.
We offer multiple API endpoints optimized for various network environments to ensure stable and fast access from
different regions, including the US, mainland China, and others.
To ensure fair allocation of API quota, we assign rate limits based on your total top-up amount:
```
| Membership Level | Total Top-up | API Limit (req/min) | Key Advantages / Ideal For |
| :--------------- | :------------ | :------------------ | :----------------------------- |
| Free | ¥0+ | 60 | Basic functions, trial users |
| VIP | ¥20+ | 1200 | Higher rate limit, for individuals/small teams |
| Premium | ¥300+ | 10000 | High rate limit, priority support, enterprise users |
The system automatically assigns you the corresponding level and rate limit based on your top-up history.
```
## API Technical Specs
OhMyGPT supports standard API key-based authentication:
```
1. Cookie-based authentication for the web interface and chat
2. API key (passed as a Bearer token) for accessing API endpoints
You can create, manage, and delete API keys in your dashboard, and set usage limits for each key.
```
We provide OpenAI-compatible interfaces supporting features such as `Audio`, `Chat`, `Completions`, `Embeddings`,
`Images`, and `Moderations`.
```
**Endpoint List:**
| Endpoint URL | Description | Recommended Use |
| :----------- | :---------- | :-------------- |
| `https://api.ohmygpt.com` | Direct US endpoint, stable connection | US-based usage |
| `https://apic.ohmygpt.com` | Cloudflare CDN (Pro), global acceleration | Outside the US |
| `https://c-z0-api-01.hash070.com` | Mainland China optimized CDN | China mainland usage |
| `https://cn2us02.opapi.win` | CN2 GIA proxy, high-quality route | General/backup use |
```
Developers simply replace the base URL `https://api.openai.com` with any of the OhMyGPT endpoints.
```
Our API is fully compatible with the OpenAI standard, so your existing code requires little or no modification to
migrate.
**Usage Tips:**
- **Location:** US users are recommended to use the direct endpoint; users in Asia or farther from the US should use
CDN or proxy endpoints.
- **Request Type:**
- **Non-streaming requests:** Recommended to use direct or proxy endpoints (more lenient timeout settings).
- **Streaming requests:** CDN endpoints are suitable (Cloudflare's 100-second timeout does not apply).
```
Our API supports multiple input and output formats:
```
- Text chat and completions
- Image generation and analysis
- Speech-to-text
- Embedding vector generation
We support streaming responses—enable `stream: true` in your request for real-time interaction.
```
## Privacy and Data Logging
Please refer to our [Terms of Service](https://www.ohmygpt.com/tos) and [Privacy Policy](https://www.ohmygpt.com/privacy).
Your data security and privacy are critically important. We use industry-leading security standards to ensure safe
data transmission and processing.
```
We only record basic request metadata (timestamp, model used, billing unit). By default, we do not log your prompts
or completions.
We guarantee no unauthorized logging of your communication data and strive to ensure concurrency, security, and
stability when handling your requests.
```
We implement multi-layered security measures to protect your API keys:
```
1. All keys are encrypted at rest
2. All transmissions use TLS encryption
3. Key-level usage limits and monitoring
4. Ability to revoke or regenerate keys at any time
You can monitor API key usage in the dashboard and act immediately if anomalies are detected.
```
## Billing and Payments
OhMyGPT provides flexible recharge options:
```
- One-time recharge: select preset or custom amounts
- Auto-recharge: set a balance threshold for automatic top-up
We use a prepaid billing model with no subscriptions or long-term contracts.
```
We support various payment options including:
```
- Credit/debit cards
- Alipay
- WeChat Pay
We’re working on integrating more payment methods. Please contact support for special requests.
```
You can view detailed usage statistics and spending history in the user dashboard:
```
- Real-time balance
- Usage breakdown by model, date, and API key
- Spending trend graphs
We offer transparent billing and reporting to help you manage and optimize your AI costs.
```
Unused credit may be refunded within 24 hours after the transaction is processed. If no refund request is made
within 24 hours, unused credit becomes non-refundable.
```
To request a refund, contact support via email. The refunded amount will be returned to your original payment
method. Platform fees are non-refundable. Note: crypto payments are non-refundable.
```
Yes, we support various types of invoices:
```
- International standard invoices
- Mainland China electronic invoices
- Japanese compliant qualified invoices (coming soon)
No matter where your company or organization is based, we’ll help with tax compliance. Contact support for invoice
requirements and procedures.
```
## Account Management
In the dashboard's API key section, you can:
```
- Create new API keys
- Set usage limits
- View usage stats
- Revoke or regenerate keys
We recommend periodically updating your keys and creating separate keys per project or app for better management.
```
Membership level is upgraded automatically based on your total top-up amount:
```
- ¥20+ total top-up: VIP
- ¥300+ total top-up: Premium
Once upgraded, you'll immediately benefit from higher rate limits and other privileges.
```
Yes, we support team sharing features. You can create separate API keys for team members and set usage limits
individually.
```
Enterprise users can contact us for custom team management solutions including multi-user control, usage reports,
and centralized billing.
```
We offer multiple support channels:
```
- [Official Telegram group](https://t.me/+SfPmr1psSNNhMzg1): quick updates and responses
- Email support: support@ohmygpt.com
- Live chat: bottom-right corner of the website for real-time help
Premium members enjoy priority support with faster response and resolution.
```
file: ./content/docs/overview/faq.mdx
meta: {
"title": "常见问题",
"description": "关于OhMyGPT的常见问题",
"icon": "CircleHelp"
}
## 入门指南
OhMyGPT提供统一的API,让您可以访问市场上各大AI模型,包括但不限于OpenAI、Claude以及Gemini。您可以在一个平台上集中管理账单,并通过我们的分析工具追踪所有使用情况。
我们确保服务的稳定性和可靠性,无需担心付款困难、地区限制或账号封禁等问题。作为2023年3月上线的老牌服务商,我们积累了丰富的运营经验和用户基础。
首先,创建一个账户并在[充值](https://next.ohmygpt.com/billing)页面添加信用额度。我们采用简单的
**随用随付(Pay-as-you-go)** 计费模式,让您根据实际需求灵活使用服务。
当您使用API或聊天界面时,我们会从您的信用额度中扣除请求成本。每个模型的价格各不相同,详细价格可在模型页面查看。
获取支持的最佳方式是加入我们的[官方Telegram群组](https://t.me/+SfPmr1psSNNhMzg1)获取最新通知和支持。
您还可以通过以下方式联系我们的客服团队:
* 电子邮件:[support@ohmygpt.com](mailto:support@ohmygpt.com)
* 在线客服:通过官网右下角聊天窗口
我们为每个模型显示明确的价格。根据模型不同,价格可能基于token数量、请求次数或其他计量单位。
我们提供简单的 **随用随付(Pay-as-you-go)** 计费模式,您可以根据实际使用情况支付费用,没有复杂的套餐或使用限额。
您可以在用户仪表板上查看完整的使用历史和消费记录,以便跟踪和管理您的支出。
计费方式和原理:
对于 GPT、Claude 和 Gemini
这样的常见大语言模型接口请求调用,出于解析成本和精确度的考虑,本站通常不会直接解析和计算用户的请求 Token,而是按照
OpenAI / Anthropic / Gemini 返回的 API 中响应的 `usage` 用量数据为标准进行精准计费。通常以官方最新的定价数据为基准值,乘以倍率,获得最终价格,例如如果一个用户使用了价值
10 美元的 gpt-4o,本站当时对于此模型的倍率是 1.1,那么用户将会被扣除 10 \* 1.1 = 11 美元的代币。
## 模型和提供商
OhMyGPT提供各种大语言模型的访问权限,包括来自主要AI实验室的前沿模型。
您可以访问[模型浏览器](https://next.ohmygpt.com/pricing)查看完整的模型列表。
我们尽可能快地添加新模型。我们与各大AI提供商保持紧密合作,能够在新模型发布后迅速集成到我们的平台上。
如果您希望OhMyGPT支持特定模型,请随时通过[官方Telegram群组](https://t.me/+SfPmr1psSNNhMzg1)或客服渠道联系我们。
我们采用行业领先的网络安全标准和技术,分布式部署了高性能计算集群,全程通信采用TLS加密。
我们为各种网络环境优化了多个API端点,确保在不同地理位置都能获得稳定、高速的服务。无论您在美国、中国大陆还是其他地区,都可以选择最适合您的API端点。
为了确保API配额的公平分配,我们根据用户的累计充值记录分配不同的速率限制:
| 会员等级 | 累计充值 | API 限制 (次/分钟) | 核心优势/适合用户 |
| :------ | :---- | :------------ | :--------------------- |
| Free | ¥0+ | 60 | 免费体验,基础功能,尝鲜用户 |
| VIP | ¥20+ | 1200 | 提升API速率,适用于个人/小型团队 |
| Premium | ¥300+ | 10000 | 高速率API,提供优先支持,高需求/企业用户 |
系统会根据您的充值记录自动给您分配对应的等级和速率限制。
## API技术规格
OhMyGPT使用标准的API密钥认证方法:
1. 基于Cookie的认证,用于Web界面和聊天室
2. API密钥(作为Bearer令牌传递),用于访问各种API端点
您可以在用户仪表板中创建、管理和删除API密钥,并为每个密钥设置使用限额。
本站提供与OpenAI官方API兼容的接口,支持`Audio`, `Chat`, `Completions`, `Embeddings`, `Images`, `Moderations`等功能。
**API端点列表:**
| 端点URL | 特点 | 推荐使用场景 |
| :-------------------------------- | :------------------------ | :------- |
| `https://api.ohmygpt.com` | 美国主站直连,稳定直连 | 美国本土调用 |
| `https://apic.ohmygpt.com` | Cloudflare CDN (Pro),全球加速 | 非美国地区调用 |
| `https://c-z0-api-01.hash070.com` | 大陆优化CDN | 中国大陆地区调用 |
| `https://cn2us02.opapi.win` | 大陆优化优质线路(CN2 GIA)反代 | 通用,备选 |
开发者只需将API请求的基础URL从`https://api.openai.com`替换为OhMyGPT提供的任一API端点即可。
我们的API完全兼容OpenAI标准,因此您现有的代码几乎无需修改就可以无缝迁移到OhMyGPT平台。
**使用建议:**
* **地理位置:** 美国用户推荐直连端点;亚洲等距离美国较远地区推荐使用CDN或反代端点。
* **请求类型:**
* **非流式请求:** 推荐使用直连或反代端点(超时限制更宽松)。
* **流式请求:** 可以使用CDN端点(通常不受Cloudflare 100秒超时限制)。
我们的API支持多种输入和输出格式:
* 文本聊天和补全
* 图像生成和分析
* 语音转文本
* 嵌入向量生成
我们支持流式响应,您可以在请求中设置`stream: true`启用流式输出,实现实时交互体验。
## 隐私和数据记录
请查看我们的[服务条款](https://www.ohmygpt.com/tos)和[隐私政策](https://www.ohmygpt.com/privacy)。
您的数据安全与隐私至关重要。我们采用行业领先的网络安全标准和技术,确保数据传输和处理的安全性。
我们只记录基本的请求元数据(时间戳、使用的模型、计量单位),默认情况下不会记录您的提示和完成内容。
我们保证不会在未经授权的情况下记录您的通信数据,确保在处理您的请求时尽可能保证高并发、安全与稳定。
我们采用多层次的安全保护措施确保您的API密钥安全:
1. 所有API密钥都经过加密存储
2. 传输过程全程采用TLS加密
3. 提供API密钥使用限额和监控功能
4. 支持随时撤销和更新API密钥
您可以在用户仪表板中随时查看API密钥的使用情况,并在发现异常时立即采取行动。
## 充值和计费系统
OhMyGPT提供灵活的充值选项:
* 一次性充值:选择预设金额或自定义充值金额
* 自动充值:设置余额阈值,低于阈值时自动充值
我们的计费系统采用预付费模式,您可以根据实际需求随时充值,没有订阅或长期合约的限制。
我们支持多种支付方式,包括:
* 信用卡/借记卡支付
* 支付宝
* 微信支付
我们正在努力整合更多支付方式,如果您有特殊需求,请联系我们的客服团队。
您可以在用户仪表板上查看详细的使用统计和消费记录:
* 实时余额显示
* 按模型、日期和API密钥筛选的使用明细
* 消费趋势图表
我们提供透明的计费和使用报告,帮助您有效管理和优化您的AI支出。
未使用的信用额度可在交易处理后二十四(24)小时内申请退款。如果在购买后二十四(24)小时内未收到退款请求,任何未使用的信用额度将不可退款。
请通过电子邮件联系我们的客服申请退款。未使用的信用额度金额将退还至您的原支付方式;平台费用不可退还。请注意,加密货币支付永远不可退款。
是的,我们支持多种发票类型:
* 国际标准Invoice
* 中国大陆电子发票
* 即将支持日本本土的适格请求书
无论您的公司或组织在世界哪个地区,我们都能助您完成税务合规,确保进项抵扣和报销合规。请联系客服了解具体的开票流程和要求。
## 账户管理
在用户仪表板的API密钥页面,您可以:
* 创建新的API密钥
* 设置使用限额
* 查看使用统计
* 撤销或更新现有密钥
我们建议定期更新您的API密钥,并为不同的项目或应用创建单独的密钥,以便更好地管理和监控使用情况。
会员等级会根据您的累计充值金额自动升级:
* 累计充值达到¥20+,自动升级为VIP会员
* 累计充值达到¥300+,自动升级为Premium会员
升级后,您将立即享受相应等级的更高API请求限制和其他优势。
是的,我们支持团队共享功能。您可以为团队成员创建单独的API密钥,并设置各自的使用限额。
企业用户还可以联系我们获取更多定制化的团队管理解决方案,如多用户管理、使用报告和集中计费等功能。
我们提供多种支持渠道:
* [官方Telegram群组](https://t.me/+SfPmr1psSNNhMzg1):获取最新通知和快速响应
* 电子邮件支持:[support@ohmygpt.com](mailto:support@ohmygpt.com)
* 在线客服:通过官网右下角聊天窗口获取实时帮助
Premium会员用户享有优先支持服务,获得更快速的响应和解决方案。
file: ./content/docs/usage/claude-code.en.mdx
meta: {
"title": "Claude Code",
"description": "Using the OhMyGPT API in Claude Code"
}
**Claude Code:** [https://github.com/anthropics/claude-code](https://github.com/anthropics/claude-code)
***
### Install
```shell
npm install -g @anthropic-ai/claude-code
```
### Configure
**Linux / MacOS:**
```shell
export ANTHROPIC_BASE_URL=https://api.ohmygpt.com
export ANTHROPIC_API_KEY=
```
### Use
```shell
claude
```
Please refer to the detailed usage method: [https://docs.anthropic.com/en/docs/claude-code/overview](https://docs.anthropic.com/en/docs/claude-code/overview)
file: ./content/docs/usage/claude-code.mdx
meta: {
"title": "Claude Code",
"description": "在 Claude Code 中使用 OhMyGPT API"
}
**Claude Code:** [https://github.com/anthropics/claude-code](https://github.com/anthropics/claude-code)
***
### 安装
```shell
npm install -g @anthropic-ai/claude-code
```
### 配置
**Linux / MacOS:**
```shell
export ANTHROPIC_BASE_URL=https://api.ohmygpt.com
export ANTHROPIC_API_KEY=
```
### 使用
```shell
claude
```
详细使用方法请参考: [https://docs.anthropic.com/en/docs/claude-code/overview](https://docs.anthropic.com/en/docs/claude-code/overview)
file: ./content/docs/usage/codex.en.mdx
meta: {
"title": "CodeX",
"description": "Using the OhMyGPT API in CodeX"
}
**Codex:** [https://github.com/openai/codex](https://github.com/openai/codex)
***
### Install
```shell
npm install -g @openai/codex
```
### Configure
#### Modify the configuration file
Configuration file path: `~/.codex/config.json`
template:
```json
{
"model": "gpt-4.1-nano",
"provider": "omg",
"providers": {
"omg": {
"name": "OhMyGPT",
"baseURL": "https://c-z0-api-01.hash070.com/v1",
"envKey": "OMG_API_KEY"
}
}
}
```
#### Set environment variables
**Linux / MacOS:**
```shell
export OMG_API_KEY=
```
**Windows:**
```shell
setx OMG_API_KEY
```
### Use
```shell
codex
```
Please refer to the detailed usage method: [https://github.com/openai/codex](https://github.com/openai/codex)
file: ./content/docs/usage/codex.mdx
meta: {
"title": "CodeX",
"description": "在 CodeX 中使用 OhMyGPT API"
}
**Codex:** [https://github.com/openai/codex](https://github.com/openai/codex)
***
### 安装
```shell
npm install -g @openai/codex
```
### 配置
#### 修改配置文件
配置文件路径: `~/.codex/config.json`
模板:
```json
{
"model": "gpt-4.1-nano",
"provider": "omg",
"providers": {
"omg": {
"name": "OhMyGPT",
"baseURL": "https://c-z0-api-01.hash070.com/v1",
"envKey": "OMG_API_KEY"
}
}
}
```
#### 设置环境变量
**Linux / MacOS:**
```shell
export OMG_API_KEY=
```
**Windows:**
```shell
setx OMG_API_KEY
```
### 使用
```shell
codex
```
详细使用方法请参考: [https://github.com/openai/codex](https://github.com/openai/codex)
file: ./content/docs/api-reference/OpenAPI/v1/completions.mdx
meta: {
"title": "Completion (Legacy)",
"full": true,
"_openapi": {
"method": "POST",
"route": "/v1/completions",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "这里仅给出示例,完整文档请查看官方文档:https://platform.openai.com/docs/api-reference/completions"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
这里仅给出示例,完整文档请查看官方文档:[https://platform.openai.com/docs/api-reference/completions](https://platform.openai.com/docs/api-reference/completions)
file: ./content/docs/api-reference/OpenAPI/v1/embeddings.mdx
meta: {
"title": "Embeddings",
"full": true,
"_openapi": {
"method": "POST",
"route": "/v1/embeddings",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "这里仅给出示例,完整参数请查看官方文档:https://platform.openai.com/docs/api-reference/embeddings"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
这里仅给出示例,完整参数请查看官方文档:[https://platform.openai.com/docs/api-reference/embeddings](https://platform.openai.com/docs/api-reference/embeddings)
file: ./content/docs/api-reference/OpenAPI/v1/models.mdx
meta: {
"title": "Models",
"full": true,
"_openapi": {
"method": "GET",
"route": "/v1/models",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "返回本站所支持的所有模型/服务,格式兼容OpenAI的格式"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
返回本站所支持的所有模型/服务,格式兼容OpenAI的格式
file: ./content/docs/api-reference/OpenAPI/v1/audio/speech.mdx
meta: {
"title": "TTS文本转语音服务",
"full": true,
"_openapi": {
"method": "POST",
"route": "/v1/audio/speech",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "OpenAI 最新款的文本转语音(TTS)模型\n\n效果非常棒,媲美真实人声,一个声音就原生支持多国语言,站长觉得它的效果比Azure的神经网络语音引擎还要牛x,对于语言学习类、AI对话交流类、AI朗读(听书、网页阅读)等方面的应用应该很有帮助。"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
OpenAI 最新款的文本转语音(TTS)模型
效果非常棒,媲美真实人声,一个声音就原生支持多国语言,站长觉得它的效果比Azure的神经网络语音引擎还要牛x,对于语言学习类、AI对话交流类、AI朗读(听书、网页阅读)等方面的应用应该很有帮助。
file: ./content/docs/api-reference/OpenAPI/v1/chat/completions.mdx
meta: {
"title": "Chat Completion",
"full": true,
"_openapi": {
"method": "POST",
"route": "/v1/chat/completions",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "OpenAI的ChatCompletion接口\n\n支持OpenAI所有的Chat模型,包括最新版本的模型\n\n关于该接口的详细参数您可以查阅OpenAI的官方文档:https://platform.openai.com/docs/api-reference/chat/create\n\n您还可以通过此接口,以OpenAI ChatCompletion API的格式,调用许多非OpenAI模型,例如Anthropic的Claude系列模型,以及TA、ChatGLM、Cohere等等,**具体支持的模型列表请以网站设置页面上的模型列表为准**,文档中的内容可能不会及时维护\n\n### Gemini系列模型JSON模式支持[24-1109更新]\n\n参考文档:\nhttps://ai.google.dev/api/generate-content#v1beta.GenerationConfig\nhttps://platform.openai.com/docs/api-reference/chat/create\n\n#### 具体实现细节\n\n简单地转换一下数据格式而已:\n\n```\nif (body.response_format.type === 'text'):\n{\nreq.generation_config.responseMimeType='text/plain'\n}\nelif (body.response_format.type === 'json_object'):\n{\nreq.generation_config.responseMimeType='application/json'\n}\nelif (body.response_format.type === 'json_schema'):\n{\nreq.generation_config.responseMimeType='application/json',\nreq.generation_config.responseSchema=body.json_schema\n}\n```\n\n示例请求:\n```json\n{\n \"model\": \"gemini-1.5-pro-002\",\n \"messages\": [\n {\n \"role\": \"user\",\n \"content\": \"What is the weather in SF CA?\"\n }\n ],\n \"stream\": false,\n \"response_format\": {\n \"type\": \"json_object\"\n }\n}\n```\n\n响应内容:\n```json\n{\n \"id\": \"chatcmpl-8dImtLWPeWwKaJUPX4iazoKba4FVS\",\n \"object\": \"chat.completion\",\n \"created\": 1731147163,\n \"model\": \"gemini-1.5-pro-002\",\n \"choices\": [\n {\n \"index\": 0,\n \"message\": {\n \"role\": \"assistant\",\n \"content\": \"{\\\"location\\\": \\\"San Francisco, CA\\\", \\\"weather\\\": \\\"I do not have access to real-time information, such as live weather updates. For the latest weather information, please check a reliable weather app or your local news.\\\"}\\n\"\n },\n \"finish_reason\": \"stop\"\n }\n ],\n \"usage\": {\n \"prompt_tokens\": 9,\n \"completion_tokens\": 50,\n \"total_tokens\": 59\n }\n}\n```\n\n示例请求:\n```json\n{\n \"model\": \"gemini-1.5-pro-002\",\n \"messages\": [\n {\n \"role\": \"user\",\n \"content\": \"What is the weather in SF CA?\"\n }\n ],\n \"stream\": false,\n \"response_format\": {\n \"type\": \"json_schema\",\n \"json_schema\": {\n \"name\": \"get_current_weather\",\n \"description\": \"Get the current weather in a given location\",\n \"parameters\": {\n \"type\": \"object\",\n \"properties\": {\n \"location\": {\n \"type\": \"string\",\n \"description\": \"The city and state, e.g. San Francisco, CA\"\n },\n \"unit\": {\n \"type\": \"string\",\n \"enum\": [\n \"celsius\",\n \"fahrenheit\"\n ]\n }\n },\n \"required\": [\n \"location\"\n ]\n }\n }\n }\n}\n```\n\n响应内容:\n```json\n{\n \"id\": \"chatcmpl-7nh9pv8TFs9vCwUcThfCNpDakonsL\",\n \"object\": \"chat.completion\",\n \"created\": 1731147392,\n \"model\": \"gemini-1.5-pro-002\",\n \"choices\": [\n {\n \"index\": 0,\n \"message\": {\n \"role\": \"assistant\",\n \"content\": \"{\\\"location\\\": \\\"San Francisco, CA\\\", \\\"weather\\\": {\\\"forecast\\\": [{\\\"date\\\": \\\"2024/01/20\\\", \\\"temperature\\\": \\\"12°C\\\", \\\"condition\\\": \\\"Cloudy\\\"}, {\\\"date\\\": \\\"2024/01/21\\\", \\\"temperature\\\": \\\"13°C\\\", \\\"condition\\\": \\\"Partly Cloudy\\\"}, {\\\"date\\\": \\\"2024/01/22\\\", \\\"temperature\\\": \\\"14°C\\\", \\\"condition\\\": \\\"Sunny\\\"}]}, \\\"current_condition\\\": {\\\"temperature\\\": \\\"12°C\\\", \\\"condition\\\": \\\"Cloudy\\\", \\\"wind\\\": \\\"10 mph\\\", \\\"humidity\\\": \\\"70%\\\"}}\\n\"\n },\n \"finish_reason\": \"stop\"\n }\n ],\n \"usage\": {\n \"prompt_tokens\": 9,\n \"completion_tokens\": 146,\n \"total_tokens\": 155\n }\n}\n```\n### Claude系列模型Tools函数调用支持[24-1107更新]\n\n最近有用户反馈关于Claude系列模型在OpenAI兼容接口中的函数调用参数支持问题,因此于24-1107完成了相关的兼容性适配,现在您可以通过OpenAI兼容接口的Tools格式调用Claude系列模型,同时返回OpenAI格式的Tools响应数据。\n\n#### 具体实现细节:\n\nClaude与OpenAI原生接口的ToolsCall输入输出都有一些区别,实现这个兼容花了一点心思,具体细节如下:\n\n**输入部分处理:**\n\n对于OpenAI到Claude请求体的`tool_choice`参数的转换\n\n```\nOpenAI body.parallel_tool_calls ==如果存在 则 取反==> Claude body.tool_choice.disable_parallel_tool_use\nOpenAI body.tool_choice.type ==> Claude body.tool_choice.type\nOpenAI body.tool_choice.function.name ==> Claude body.tool_choice.name\n```\n\n其中:\n\n```\n1. 当 `tool_choice` 为字符串类型时:\n - 如果值为 `\"none\"`,则 Claude 的 `tool_choices` 设置为 `undefined`\n - 如果值为 `\"auto\"`,则 Claude 的 `tool_choices` 设置为 `{ type: 'auto' }`\n - 如果值为 `\"required\"`,则 Claude 的 `tool_choices` 设置为 `{ type: 'any' }`\n\n2. 当 `tool_choice` 为对象类型时:\n - Claude 的 `tool_choices` 将被设置为包含以下内容的对象:\n - `type` 固定设置为 `'tool'`\n - `name` 设置为 OpenAI 请求中 `tool_choice.function.name` 的值\n\n3. 对于 `tools` 参数的转换:\n - 如果 OpenAI 请求中存在 `tools` 数组,则对数组中的每个工具对象进行转换\n - 对于每个类型为 `'function'` 的工具对象,转换规则如下:\n - `tool.function.name` ==> Claude `tools[].name`\n - `tool.function.description` ==> Claude `tools[].description`\n - `tool.function.parameters` ==> Claude `tools[].input_schema`\n - 如果工具对象不符合上述结构,则该参数不会被发送到Claude\n - 如果 OpenAI 请求中不存在 `tools` 数组,Claude 的 `tools` 参数不会被发送到Claude\n```\n\n**输出部分处理:**\n\nClaude的流式输出与OpenAI的格式有较大差异,需要进行适配转换。主要包括以下几种情况:\n\n```\n1. 纯文本输出转换:\n - 当Claude返回 `content_block_delta` 且类型为 `text_delta` 时,需转换为OpenAI的格式:\n - 将 text_delta.text 转换到 OpenAI 的 choices[0].delta.content 中\n\n2. 工具调用输出转换:\n - 当Claude返回工具调用相关事件时,需要进行以下转换:\n - 当收到 `content_block_start` 且类型为 `tool_use` 时:\n - 生成工具调用的初始结构,包含 tool_calls 数组\n - 将 Claude 的 tool_use.name 转换为 OpenAI 的 function.name\n - 生成一个唯一的 tool call id\n - 工具调用的 index 需要从 Claude 的基于1的索引转换为基于0的索引\n\n - 当收到 `content_block_delta` 且类型为 `input_json_delta` 时:\n - 将 partial_json 内容追加到对应工具调用的 arguments 字段中\n\n3. 结束标识转换:\n - 当Claude返回 `message_delta` 且 stop_reason 为 \"tool_use\" 时:\n - 设置 OpenAI 格式的 finish_reason 为 \"tool_calls\"\n - 当Claude返回 `message_stop` 时:\n - 输出 OpenAI 格式的 usage 信息\n - 最后输出 \"[DONE]\" 标识\n\n4. 通用字段转换:\n - 为所有输出添加 OpenAI 格式所需的通用字段:\n - id: `chatcmpl-${随机ID}`\n - object: \"chat.completion.chunk\"\n - created: 请求开始时间戳\n - model: 模型名称\n - system_fingerprint: `fp_${8位随机ID}`\n - choices[0].index: 0\n - choices[0].logprobs: null\n```\n\n#### 示例请求:\n```json\n{\n \"model\": \"claude-3-5-haiku\",\n \"messages\": [\n {\n \"role\": \"user\",\n \"content\": \"What's the weather like in Boston today?\"\n }\n ],\n \"tools\": [\n {\n \"type\": \"function\",\n \"function\": {\n \"name\": \"get_current_weather\",\n \"description\": \"Get the current weather in a given location\",\n \"parameters\": {\n \"type\": \"object\",\n \"properties\": {\n \"location\": {\n \"type\": \"string\",\n \"description\": \"The city and state, e.g. San Francisco, CA\"\n },\n \"unit\": {\n \"type\": \"string\",\n \"enum\": [\"celsius\", \"fahrenheit\"]\n }\n },\n \"required\": [\"location\"]\n }\n }\n }\n ],\n \"tool_choice\": \"auto\",\n \"stream\": false\n}\n```\n\n非流返回(`stream=false`)\n```json\n{\n \"id\": \"chatcmpl-H84t7g0CY5f4Gqg7KviVCXzJ4EIJ0\",\n \"object\": \"chat.completion\",\n \"created\": 1730973989,\n \"model\": \"claude-3-5-haiku\",\n \"choices\": [\n {\n \"index\": 0,\n \"message\": {\n \"role\": \"assistant\",\n \"content\": null,\n \"tool_calls\": [\n {\n \"id\": \"toolu_01HB4BABmfcNDCJKG5eiVmQv\",\n \"type\": \"function\",\n \"function\": {\n \"name\": \"get_current_weather\",\n \"arguments\": \"{\\\"location\\\":\\\"Boston, MA\\\",\\\"unit\\\":\\\"fahrenheit\\\"}\"\n }\n }\n ],\n \"refusal\": null\n },\n \"logprobs\": null,\n \"finish_reason\": \"tool_calls\"\n },\n {\n \"index\": 0,\n \"message\": {\n \"role\": \"assistant\",\n \"content\": \"I'll help you check the current weather in Boston. I'll retrieve the weather information using the get_current_weather function.\",\n \"refusal\": null\n },\n \"logprobs\": null,\n \"finish_reason\": \"stop\"\n }\n ],\n \"usage\": {\n \"prompt_tokens\": 376,\n \"completion_tokens\": 104,\n \"total_tokens\": 480\n }\n}\n```\n\n流返回(`stream=true`):\n```json\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\"\",\"refusal\":null},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\"I'll\"},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\" help\"},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\" you find out\"},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\" the current weather in Boston\"},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\".\"},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\" I\"},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\"'ll\"},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\" retrieve\"},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\" the current\"},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\" weather information\"},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\" for\"},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\" you\"},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\".\"},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":null,\"tool_calls\":[{\"index\":0,\"id\":\"toolu_01RdBwK8GsN7sm6dyDteDc3e\",\"type\":\"function\",\"function\":{\"name\":\"get_current_weather\",\"arguments\":\"\"}}],\"refusal\":null},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"tool_calls\":[{\"index\":0,\"function\":{\"arguments\":\"{\\\"locati\"}}]},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"tool_calls\":[{\"index\":0,\"function\":{\"arguments\":\"on\\\": \\\"Bosto\"}}]},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"tool_calls\":[{\"index\":0,\"function\":{\"arguments\":\"n, M\"}}]},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"tool_calls\":[{\"index\":0,\"function\":{\"arguments\":\"A\\\"\"}}]},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"tool_calls\":[{\"index\":0,\"function\":{\"arguments\":\", \\\"unit\\\": \\\"f\"}}]},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"tool_calls\":[{\"index\":0,\"function\":{\"arguments\":\"ahrenh\"}}]},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{\"tool_calls\":[{\"index\":0,\"function\":{\"arguments\":\"eit\\\"}\"}}]},\"logprobs\":null,\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"system_fingerprint\":\"fp_t5VoJU6E\",\"choices\":[{\"index\":0,\"delta\":{},\"logprobs\":null,\"finish_reason\":\"tool_calls\"}]}\n\ndata: {\"id\":\"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ\",\"object\":\"chat.completion.chunk\",\"created\":1730992326,\"model\":\"claude-3-5-haiku\",\"choices\":[],\"usage\":{\"prompt_tokens\":376,\"completion_tokens\":100,\"total_tokens\":476,\"prompt_tokens_details\":{\"cached_tokens\":0},\"completion_tokens_details\":{\"reasoning_tokens\":0}}}\n\ndata: [DONE]\n\n\n```\n\n### Gemini Pro Vision使用示例\n\n可以完全参照OpenAI的Vision说明:https://platform.openai.com/docs/guides/vision\n\n**示例输入:**\n\n```json\n{\n \"model\": \"gemini-pro-vision\",\n \"messages\": [\n {\n \"role\": \"user\",\n \"content\": [\n {\n \"type\": \"text\", \"text\": \"描述一下这张图片\"\n },\n {\n \"type\": \"image_url\",\n \"image_url\": \"https://pbs.twimg.com/media/GBEB1CbbIAAC28o?format=jpg&name=small\"\n }\n ]\n }\n ],\n \"stream\": false\n}\n```\n\n**注:同样也支持Base64作为图像输入的,而且Base64可靠性更高,推荐Base64,这里放链接是为了防止字数太多。**\n\n返回结果:\n\n```json\n{\n \"id\": \"chatcmpl-gPyHaMj77C8Uca3UudUL5zxvAvI3N\",\n \"object\": \"chat.completion\",\n \"created\": 1702560711,\n \"model\": \"gemini-pro-vision\",\n \"choices\": [\n {\n \"index\": 0,\n \"message\": {\n \"role\": \"assistant\",\n \"content\": \" 这是五个不同角色的表情包。他们分别是:\\n- 胡桃\\n- 宵宫\\n- 早柚\\n- 刻晴\\n- 珊瑚宫心海\"\n },\n \"finish_reason\": \"stop\"\n }\n ],\n \"usage\": {\n \"prompt_tokens\": 8,\n \"completion_tokens\": 48,\n \"total_tokens\": 56\n }\n}\n```\n\n流式请求(`\"stream\": true`)返回结果:\n\n```json\ndata: {\"id\":\"chatcmpl-6tzfeCctklU06xs8BmDo3b1YcCold\",\"object\":\"chat.completion.chunk\",\"created\":1702562069,\"model\":\"gemini-pro-vision\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\" 这是五个不同角色的表情包。他们分别是:\\n- 胡桃\\n- 宵宫\\n- 早柚\\n- 刻晴\\n- 珊瑚\"},\"finish_reason\":null}]}\n\ndata: {\"id\":\"chatcmpl-6tzfeCctklU06xs8BmDo3b1YcCold\",\"object\":\"chat.completion.chunk\",\"created\":1702562069,\"model\":\"gemini-pro-vision\",\"choices\":[{\"index\":0,\"delta\":{\"role\":\"assistant\",\"content\":\"宫心海\"},\"finish_reason\":null}]}\n\ndata: [DONE]\n```"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
OpenAI的ChatCompletion接口
支持OpenAI所有的Chat模型,包括最新版本的模型
关于该接口的详细参数您可以查阅OpenAI的官方文档:[https://platform.openai.com/docs/api-reference/chat/create](https://platform.openai.com/docs/api-reference/chat/create)
您还可以通过此接口,以OpenAI ChatCompletion API的格式,调用许多非OpenAI模型,例如Anthropic的Claude系列模型,以及TA、ChatGLM、Cohere等等,**具体支持的模型列表请以网站设置页面上的模型列表为准**,文档中的内容可能不会及时维护
### Gemini系列模型JSON模式支持\[24-1109更新]
参考文档:
[https://ai.google.dev/api/generate-content#v1beta.GenerationConfig](https://ai.google.dev/api/generate-content#v1beta.GenerationConfig)
[https://platform.openai.com/docs/api-reference/chat/create](https://platform.openai.com/docs/api-reference/chat/create)
#### 具体实现细节
简单地转换一下数据格式而已:
```
if (body.response_format.type === 'text'):
{
req.generation_config.responseMimeType='text/plain'
}
elif (body.response_format.type === 'json_object'):
{
req.generation_config.responseMimeType='application/json'
}
elif (body.response_format.type === 'json_schema'):
{
req.generation_config.responseMimeType='application/json',
req.generation_config.responseSchema=body.json_schema
}
```
示例请求:
```json
{
"model": "gemini-1.5-pro-002",
"messages": [
{
"role": "user",
"content": "What is the weather in SF CA?"
}
],
"stream": false,
"response_format": {
"type": "json_object"
}
}
```
响应内容:
```json
{
"id": "chatcmpl-8dImtLWPeWwKaJUPX4iazoKba4FVS",
"object": "chat.completion",
"created": 1731147163,
"model": "gemini-1.5-pro-002",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{\"location\": \"San Francisco, CA\", \"weather\": \"I do not have access to real-time information, such as live weather updates. For the latest weather information, please check a reliable weather app or your local news.\"}\n"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 50,
"total_tokens": 59
}
}
```
示例请求:
```json
{
"model": "gemini-1.5-pro-002",
"messages": [
{
"role": "user",
"content": "What is the weather in SF CA?"
}
],
"stream": false,
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": [
"celsius",
"fahrenheit"
]
}
},
"required": [
"location"
]
}
}
}
}
```
响应内容:
```json
{
"id": "chatcmpl-7nh9pv8TFs9vCwUcThfCNpDakonsL",
"object": "chat.completion",
"created": 1731147392,
"model": "gemini-1.5-pro-002",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{\"location\": \"San Francisco, CA\", \"weather\": {\"forecast\": [{\"date\": \"2024/01/20\", \"temperature\": \"12°C\", \"condition\": \"Cloudy\"}, {\"date\": \"2024/01/21\", \"temperature\": \"13°C\", \"condition\": \"Partly Cloudy\"}, {\"date\": \"2024/01/22\", \"temperature\": \"14°C\", \"condition\": \"Sunny\"}]}, \"current_condition\": {\"temperature\": \"12°C\", \"condition\": \"Cloudy\", \"wind\": \"10 mph\", \"humidity\": \"70%\"}}\n"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 146,
"total_tokens": 155
}
}
```
### Claude系列模型Tools函数调用支持\[24-1107更新]
最近有用户反馈关于Claude系列模型在OpenAI兼容接口中的函数调用参数支持问题,因此于24-1107完成了相关的兼容性适配,现在您可以通过OpenAI兼容接口的Tools格式调用Claude系列模型,同时返回OpenAI格式的Tools响应数据。
#### 具体实现细节:
Claude与OpenAI原生接口的ToolsCall输入输出都有一些区别,实现这个兼容花了一点心思,具体细节如下:
**输入部分处理:**
对于OpenAI到Claude请求体的`tool_choice`参数的转换
```
OpenAI body.parallel_tool_calls ==如果存在 则 取反==> Claude body.tool_choice.disable_parallel_tool_use
OpenAI body.tool_choice.type ==> Claude body.tool_choice.type
OpenAI body.tool_choice.function.name ==> Claude body.tool_choice.name
```
其中:
```
1. 当 `tool_choice` 为字符串类型时:
- 如果值为 `"none"`,则 Claude 的 `tool_choices` 设置为 `undefined`
- 如果值为 `"auto"`,则 Claude 的 `tool_choices` 设置为 `{ type: 'auto' }`
- 如果值为 `"required"`,则 Claude 的 `tool_choices` 设置为 `{ type: 'any' }`
2. 当 `tool_choice` 为对象类型时:
- Claude 的 `tool_choices` 将被设置为包含以下内容的对象:
- `type` 固定设置为 `'tool'`
- `name` 设置为 OpenAI 请求中 `tool_choice.function.name` 的值
3. 对于 `tools` 参数的转换:
- 如果 OpenAI 请求中存在 `tools` 数组,则对数组中的每个工具对象进行转换
- 对于每个类型为 `'function'` 的工具对象,转换规则如下:
- `tool.function.name` ==> Claude `tools[].name`
- `tool.function.description` ==> Claude `tools[].description`
- `tool.function.parameters` ==> Claude `tools[].input_schema`
- 如果工具对象不符合上述结构,则该参数不会被发送到Claude
- 如果 OpenAI 请求中不存在 `tools` 数组,Claude 的 `tools` 参数不会被发送到Claude
```
**输出部分处理:**
Claude的流式输出与OpenAI的格式有较大差异,需要进行适配转换。主要包括以下几种情况:
```
1. 纯文本输出转换:
- 当Claude返回 `content_block_delta` 且类型为 `text_delta` 时,需转换为OpenAI的格式:
- 将 text_delta.text 转换到 OpenAI 的 choices[0].delta.content 中
2. 工具调用输出转换:
- 当Claude返回工具调用相关事件时,需要进行以下转换:
- 当收到 `content_block_start` 且类型为 `tool_use` 时:
- 生成工具调用的初始结构,包含 tool_calls 数组
- 将 Claude 的 tool_use.name 转换为 OpenAI 的 function.name
- 生成一个唯一的 tool call id
- 工具调用的 index 需要从 Claude 的基于1的索引转换为基于0的索引
- 当收到 `content_block_delta` 且类型为 `input_json_delta` 时:
- 将 partial_json 内容追加到对应工具调用的 arguments 字段中
3. 结束标识转换:
- 当Claude返回 `message_delta` 且 stop_reason 为 "tool_use" 时:
- 设置 OpenAI 格式的 finish_reason 为 "tool_calls"
- 当Claude返回 `message_stop` 时:
- 输出 OpenAI 格式的 usage 信息
- 最后输出 "[DONE]" 标识
4. 通用字段转换:
- 为所有输出添加 OpenAI 格式所需的通用字段:
- id: `chatcmpl-${随机ID}`
- object: "chat.completion.chunk"
- created: 请求开始时间戳
- model: 模型名称
- system_fingerprint: `fp_${8位随机ID}`
- choices[0].index: 0
- choices[0].logprobs: null
```
#### 示例请求:
```json
{
"model": "claude-3-5-haiku",
"messages": [
{
"role": "user",
"content": "What's the weather like in Boston today?"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
}
],
"tool_choice": "auto",
"stream": false
}
```
非流返回(`stream=false`)
```json
{
"id": "chatcmpl-H84t7g0CY5f4Gqg7KviVCXzJ4EIJ0",
"object": "chat.completion",
"created": 1730973989,
"model": "claude-3-5-haiku",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "toolu_01HB4BABmfcNDCJKG5eiVmQv",
"type": "function",
"function": {
"name": "get_current_weather",
"arguments": "{\"location\":\"Boston, MA\",\"unit\":\"fahrenheit\"}"
}
}
],
"refusal": null
},
"logprobs": null,
"finish_reason": "tool_calls"
},
{
"index": 0,
"message": {
"role": "assistant",
"content": "I'll help you check the current weather in Boston. I'll retrieve the weather information using the get_current_weather function.",
"refusal": null
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 376,
"completion_tokens": 104,
"total_tokens": 480
}
}
```
流返回(`stream=true`):
```json
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":"","refusal":null},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":"I'll"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":" help"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":" you find out"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":" the current weather in Boston"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":"."},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":" I"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":"'ll"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":" retrieve"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":" the current"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":" weather information"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":" for"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":" you"},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":"."},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"role":"assistant","content":null,"tool_calls":[{"index":0,"id":"toolu_01RdBwK8GsN7sm6dyDteDc3e","type":"function","function":{"name":"get_current_weather","arguments":""}}],"refusal":null},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"tool_calls":[{"index":0,"function":{"arguments":"{\"locati"}}]},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"tool_calls":[{"index":0,"function":{"arguments":"on\": \"Bosto"}}]},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"tool_calls":[{"index":0,"function":{"arguments":"n, M"}}]},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"tool_calls":[{"index":0,"function":{"arguments":"A\""}}]},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"tool_calls":[{"index":0,"function":{"arguments":", \"unit\": \"f"}}]},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"tool_calls":[{"index":0,"function":{"arguments":"ahrenh"}}]},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{"tool_calls":[{"index":0,"function":{"arguments":"eit\"}"}}]},"logprobs":null,"finish_reason":null}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","system_fingerprint":"fp_t5VoJU6E","choices":[{"index":0,"delta":{},"logprobs":null,"finish_reason":"tool_calls"}]}
data: {"id":"chatcmpl-t5VoJU6Et68AzGIMAaDYjGydoQ8HQ","object":"chat.completion.chunk","created":1730992326,"model":"claude-3-5-haiku","choices":[],"usage":{"prompt_tokens":376,"completion_tokens":100,"total_tokens":476,"prompt_tokens_details":{"cached_tokens":0},"completion_tokens_details":{"reasoning_tokens":0}}}
data: [DONE]
```
### Gemini Pro Vision使用示例
可以完全参照OpenAI的Vision说明:[https://platform.openai.com/docs/guides/vision](https://platform.openai.com/docs/guides/vision)
**示例输入:**
```json
{
"model": "gemini-pro-vision",
"messages": [
{
"role": "user",
"content": [
{
"type": "text", "text": "描述一下这张图片"
},
{
"type": "image_url",
"image_url": "https://pbs.twimg.com/media/GBEB1CbbIAAC28o?format=jpg&name=small"
}
]
}
],
"stream": false
}
```
**注:同样也支持Base64作为图像输入的,而且Base64可靠性更高,推荐Base64,这里放链接是为了防止字数太多。**
返回结果:
```json
{
"id": "chatcmpl-gPyHaMj77C8Uca3UudUL5zxvAvI3N",
"object": "chat.completion",
"created": 1702560711,
"model": "gemini-pro-vision",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": " 这是五个不同角色的表情包。他们分别是:\n- 胡桃\n- 宵宫\n- 早柚\n- 刻晴\n- 珊瑚宫心海"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 8,
"completion_tokens": 48,
"total_tokens": 56
}
}
```
流式请求(`"stream": true`)返回结果:
```json
data: {"id":"chatcmpl-6tzfeCctklU06xs8BmDo3b1YcCold","object":"chat.completion.chunk","created":1702562069,"model":"gemini-pro-vision","choices":[{"index":0,"delta":{"role":"assistant","content":" 这是五个不同角色的表情包。他们分别是:\n- 胡桃\n- 宵宫\n- 早柚\n- 刻晴\n- 珊瑚"},"finish_reason":null}]}
data: {"id":"chatcmpl-6tzfeCctklU06xs8BmDo3b1YcCold","object":"chat.completion.chunk","created":1702562069,"model":"gemini-pro-vision","choices":[{"index":0,"delta":{"role":"assistant","content":"宫心海"},"finish_reason":null}]}
data: [DONE]
```
file: ./content/docs/other-api/Other-API/api/v1/azure/get-tts-list.mdx
meta: {
"title": "Azure 获取TTS 语音列表",
"full": true,
"_openapi": {
"method": "GET",
"route": "/api/v1/azure/get-tts-list",
"toc": [],
"structuredData": {
"headings": [],
"contents": []
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
file: ./content/docs/other-api/Other-API/api/v1/azure/tts.mdx
meta: {
"title": "Azure 文本转语音",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/azure/tts",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "您可通过此接口直接访问Azure的神经网络语音模型,实现将文字转换为音频的功能。(您需要在您的API密钥上勾选`azure-tts-1`权限才可以调用此接口\n\n定价:\n\n最终代币消耗为:input的字符串长度 * 5\n\n参考:\n\n[SSML](https://learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-synthesis-markup-voice)"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
您可通过此接口直接访问Azure的神经网络语音模型,实现将文字转换为音频的功能。(您需要在您的API密钥上勾选`azure-tts-1`权限才可以调用此接口
定价:
最终代币消耗为:input的字符串长度 \* 5
参考:
[SSML](https://learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-synthesis-markup-voice)
file: ./content/docs/developer/OAuth-API/api/v1/user/oauth/issue-token.mdx
meta: {
"title": "申请access_token",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/user/oauth/issue-token",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "OAuth APP服务端通过自己的client_id+client_secret以及从用户那里拿到的code请求OAuth Access Token\n\n拿到用户的OAuth Token后,即可调用各种开放API以访问用户授权的资源\n\n但需要注意处理OAuth Token被撤销的情况\n\n用户可以随时撤销对您的OAuth App的授权,此时会返回4xx错误+如下格式的响应:\n\n```json\n{\n \"statusCode\": 401,\n \"message\": \"Incorrect OhMyGPT OAuth token provided. Please try to re-authenticate with the OAuth provider.\",\n \"errorType\": \"oauth_invalid_token_error\",\n \"data\": null\n}\n```\n\n只要发现 `errorType` 为 `oauth_invalid_token_error` 即证明此Token无效,可丢弃此Token并要求用户重新授权\n\n如果遇到余额不足的错误:\n\n```json\n{\n \"statusCode\": 402,\n \"message\": \"User balance is insufficient, your request has been rejected, please recharge in time at https://www.ohmygpt.com/pay .\",\n \"errorType\": \"insufficient_balance_error\",\n \"data\": null\n}\n```\n\n以上报错表示用户余额不足,此时该用户大部分的API调用权限将被限制,建议提示用户前往网站进行充值以解除限制\n"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
OAuth APP服务端通过自己的client\_id+client\_secret以及从用户那里拿到的code请求OAuth Access Token
拿到用户的OAuth Token后,即可调用各种开放API以访问用户授权的资源
但需要注意处理OAuth Token被撤销的情况
用户可以随时撤销对您的OAuth App的授权,此时会返回4xx错误+如下格式的响应:
```json
{
"statusCode": 401,
"message": "Incorrect OhMyGPT OAuth token provided. Please try to re-authenticate with the OAuth provider.",
"errorType": "oauth_invalid_token_error",
"data": null
}
```
只要发现 `errorType` 为 `oauth_invalid_token_error` 即证明此Token无效,可丢弃此Token并要求用户重新授权
如果遇到余额不足的错误:
```json
{
"statusCode": 402,
"message": "User balance is insufficient, your request has been rejected, please recharge in time at https://www.ohmygpt.com/pay .",
"errorType": "insufficient_balance_error",
"data": null
}
```
以上报错表示用户余额不足,此时该用户大部分的API调用权限将被限制,建议提示用户前往网站进行充值以解除限制
file: ./content/docs/files-api/Files-API/api/v1/user/files/delete-by-fuid.mdx
meta: {
"title": "删除文件",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/user/files/delete-by-fuid",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "# 简介\n\n删除文件\n\n# 参数描述\n\n| 字段名 | 类型 | 必需 | 示例值 | 备注 |\n|-----------------|---------|-------|-----------------|---------------------|\n| fileUniqueId | string | 是 | ENthMCy_5zr5zN3GRJseM | 文件UID 必填 |\n\n调用此接口需要提供有效的APIKey凭证,如果启用了APIKey权限检查,需要具备 `file-v1` 的权限"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
# 简介
删除文件
# 参数描述
| 字段名 | 类型 | 必需 | 示例值 | 备注 |
| ------------ | ------ | -- | ---------------------- | -------- |
| fileUniqueId | string | 是 | ENthMCy\_5zr5zN3GRJseM | 文件UID 必填 |
调用此接口需要提供有效的APIKey凭证,如果启用了APIKey权限检查,需要具备 `file-v1` 的权限
file: ./content/docs/files-api/Files-API/api/v1/user/files/get-metadata.mdx
meta: {
"title": "用户元数据查询 (by fileUinqueIds)",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/user/files/get-metadata",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "# 简介\n\n根据fileId查询已上传文件的元数据\n\n# 参数描述\n\n| 字段名 | 类型 | 必需 | 示例值 | 备注 |\n|----------|----------|-------|--------------|--------------------------|\n| fileUniqueIds | string | true | [\"ENthMCy_5zr5zN3GRJseM\"]| 查询的Id |\n\n调用此接口需要提供有效的APIKey凭证,如果启用了APIKey权限检查,需要具备 `file-v1` 的权限"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
# 简介
根据fileId查询已上传文件的元数据
# 参数描述
| 字段名 | 类型 | 必需 | 示例值 | 备注 |
| ------------- | ------ | ---- | --------------------------- | ----- |
| fileUniqueIds | string | true | \["ENthMCy\_5zr5zN3GRJseM"] | 查询的Id |
调用此接口需要提供有效的APIKey凭证,如果启用了APIKey权限检查,需要具备 `file-v1` 的权限
file: ./content/docs/files-api/Files-API/api/v1/user/files/list.mdx
meta: {
"title": "用户查询 (分页)",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/user/files/list",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "# 简介\n\n查询已上传文件\n\n# 参数描述\n\n| 字段名 | 类型 | 必需 | 示例值 | 备注 |\n|----------|----------|-------|--------------|--------------------------|\n| page | number | true | 1 | 页码 大于等于1 |\n| pageSize | number | true | 100 | 页大小 范围 [1,100] |\n| tags | array | false | [\"example\"] | 查询的文件Tag 可选 |\n| purpose | string | false | \"example\" | 查询的文件用途 可选 |\n| filename | string | false | \"example.txt\"| 查询的文件名 可选 |\n\n调用此接口需要提供有效的APIKey凭证,如果启用了APIKey权限检查,需要具备 `file-v1` 的权限"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
# 简介
查询已上传文件
# 参数描述
| 字段名 | 类型 | 必需 | 示例值 | 备注 |
| -------- | ------ | ----- | ------------- | --------------- |
| page | number | true | 1 | 页码 大于等于1 |
| pageSize | number | true | 100 | 页大小 范围 \[1,100] |
| tags | array | false | \["example"] | 查询的文件Tag 可选 |
| purpose | string | false | "example" | 查询的文件用途 可选 |
| filename | string | false | "example.txt" | 查询的文件名 可选 |
调用此接口需要提供有效的APIKey凭证,如果启用了APIKey权限检查,需要具备 `file-v1` 的权限
file: ./content/docs/files-api/Files-API/api/v1/user/files/update.mdx
meta: {
"title": "文件信息更新",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/user/files/update",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "# 简介\n\n更新文件信息\n\n# 参数描述\n\n| 字段名 | 类型 | 必需 | 示例值 | 备注 |\n|-----------------|---------|-------|-----------------|---------------------|\n| fileUniqueId | string | 是 | ENthMCy_5zr5zN3GRJseM | 文件UID 必填 |\n| filename | string | 是 | example-new.png | 新文件名 必填 |\n| purpose | integer | 否 | 0 | 文件目的 |\n| is_public | boolean | 否 | true | 是否公开 |\n| tags | array | 否 | [\"tag1\", \"tag2\"]| 新的文件Tag |\n| expires_at | string | 否 | 2024-12-31T23:59:59 | 到期时间 |\n| unset_expires_at| boolean | 否 | false | 是否取消设置到期时间 |\n\n调用此接口需要提供有效的APIKey凭证,如果启用了APIKey权限检查,需要具备 `file-v1` 的权限\n\n附:\n\n文件用途`purpose`定义:\n\n```\n{\n COMMON = 0,\n FINETUNE = 1,\n CHAT = 2,\n LLM_TMP = 3,\n OPENAI_BATCH = 4,\n ANTHROPIC_BATCH = 5,\n}\n```"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
# 简介
更新文件信息
# 参数描述
| 字段名 | 类型 | 必需 | 示例值 | 备注 |
| ------------------ | ------- | -- | ---------------------- | ---------- |
| fileUniqueId | string | 是 | ENthMCy\_5zr5zN3GRJseM | 文件UID 必填 |
| filename | string | 是 | example-new\.png | 新文件名 必填 |
| purpose | integer | 否 | 0 | 文件目的 |
| is\_public | boolean | 否 | true | 是否公开 |
| tags | array | 否 | \["tag1", "tag2"] | 新的文件Tag |
| expires\_at | string | 否 | 2024-12-31T23:59:59 | 到期时间 |
| unset\_expires\_at | boolean | 否 | false | 是否取消设置到期时间 |
调用此接口需要提供有效的APIKey凭证,如果启用了APIKey权限检查,需要具备 `file-v1` 的权限
附:
文件用途`purpose`定义:
```
{
COMMON = 0,
FINETUNE = 1,
CHAT = 2,
LLM_TMP = 3,
OPENAI_BATCH = 4,
ANTHROPIC_BATCH = 5,
}
```
file: ./content/docs/files-api/Files-API/api/v1/user/files/upload.mdx
meta: {
"title": "文件上传",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/user/files/upload",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "# 简介\n\n上传一个文件到文件存储服务中,目前此接口仅支持约100MB以下的文件上传,有计划支持大文件上传,大文件分段上传接口会在后续开发。\n\n# 参数描述\n\n| 字段名 | 类型 | 必需 | 示例值 | 备注 |\n|--------|------|------|--------|------|\n| file | file | true | 文件 | 文件数据 |\n| filename | string | true | GdIDB9HakAAiVFK.jpg | 文件名 |\n| purpose | string | true | 0 | 文件用途 |\n| is_public | string | false | true | 是否公开(可选) 默认私有 |\n| tags | string | false | [\"t1\"] | 文件标签标记(可选) 可用于筛选文件 |\n| expires_at | string | false | 2024-11-29T22:14:53+08:00 | 文件过期时间(可选) 若到期系统会自动删除 用于存储临时文件时推荐设置此属性 |\n\n调用此接口需要提供有效的APIKey凭证,如果启用了APIKey权限检查,需要具备 `file-v1` 的权限\n\n附:\n\n文件用途`purpose`定义:\n\n```\n{\n COMMON = 0,\n FINETUNE = 1,\n CHAT = 2,\n LLM_TMP = 3,\n OPENAI_BATCH = 4,\n ANTHROPIC_BATCH = 5,\n}\n```"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
# 简介
上传一个文件到文件存储服务中,目前此接口仅支持约100MB以下的文件上传,有计划支持大文件上传,大文件分段上传接口会在后续开发。
# 参数描述
| 字段名 | 类型 | 必需 | 示例值 | 备注 |
| ----------- | ------ | ----- | ------------------------- | -------------------------------------- |
| file | file | true | 文件 | 文件数据 |
| filename | string | true | GdIDB9HakAAiVFK.jpg | 文件名 |
| purpose | string | true | 0 | 文件用途 |
| is\_public | string | false | true | 是否公开(可选) 默认私有 |
| tags | string | false | \["t1"] | 文件标签标记(可选) 可用于筛选文件 |
| expires\_at | string | false | 2024-11-29T22:14:53+08:00 | 文件过期时间(可选) 若到期系统会自动删除 用于存储临时文件时推荐设置此属性 |
调用此接口需要提供有效的APIKey凭证,如果启用了APIKey权限检查,需要具备 `file-v1` 的权限
附:
文件用途`purpose`定义:
```
{
COMMON = 0,
FINETUNE = 1,
CHAT = 2,
LLM_TMP = 3,
OPENAI_BATCH = 4,
ANTHROPIC_BATCH = 5,
}
```
file: ./content/docs/developer/OAuth-API/api/v1/pay/oa/stripe/create-invoice-order.mdx
meta: {
"title": "为用户创建一个Stripe Invoice充值订单",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/pay/oa/stripe/create-invoice-order",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "方便用户在余额不足时直接充值\n\n注:调用此API的最低权限为 `trusted_advanced_access`"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
方便用户在余额不足时直接充值
注:调用此API的最低权限为 `trusted_advanced_access`
file: ./content/docs/developer/OAuth-API/api/v1/pay/oa/stripe/create-order.mdx
meta: {
"title": "为用户创建一个Stripe Checkout充值订单",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/pay/oa/stripe/create-order",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "方便用户在余额不足时直接充值\n\n注:调用此API的最低权限为 `trusted_advanced_access`"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
方便用户在余额不足时直接充值
注:调用此API的最低权限为 `trusted_advanced_access`
file: ./content/docs/developer/OAuth-API/api/v1/user/oauth/app/charge-user-balance.mdx
meta: {
"title": "收取用户费用",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/user/oauth/app/charge-user-balance",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "主动扣除用户的代币到您的开发者账户中,方便让用户支付应用的费用,不可以未经用户授权恶意扣除费用。\n\n在转到您的开发者账户时,会自动扣除约10%的手续费\n\n注:\n\n1. 调用此API的最低权限为 `trusted_advanced_access` ,因此您需要是一个已验证的开发者才能调用此接口\n2. 当且仅当返回200才可视为成功,必要时可对响应体的数据内容进行检查"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
主动扣除用户的代币到您的开发者账户中,方便让用户支付应用的费用,不可以未经用户授权恶意扣除费用。
在转到您的开发者账户时,会自动扣除约10%的手续费
注:
1. 调用此API的最低权限为 `trusted_advanced_access` ,因此您需要是一个已验证的开发者才能调用此接口
2. 当且仅当返回200才可视为成功,必要时可对响应体的数据内容进行检查
file: ./content/docs/developer/OAuth-API/api/v1/user/oauth/app/get-user-admin-token.mdx
meta: {
"title": "通过OAuth Token读取用户管理Token",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/user/oauth/app/get-user-admin-token",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "获取一个用户管理Token\n\n注:\n\n1. 调用此API的最低权限为 `trusted_full_access` ,您需要是一个已验证的开发者才有机会调用此接口\n2. 当且仅当返回200才可视为成功,必要时可对响应体的数据内容进行检查"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
获取一个用户管理Token
注:
1. 调用此API的最低权限为 `trusted_full_access` ,您需要是一个已验证的开发者才有机会调用此接口
2. 当且仅当返回200才可视为成功,必要时可对响应体的数据内容进行检查
file: ./content/docs/developer/OAuth-API/api/v1/user/oauth/app/query-user-balance.mdx
meta: {
"title": "读取用户余额信息",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/user/oauth/app/query-user-balance",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "注:调用此API的最低权限为 `general_api_access`"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
注:调用此API的最低权限为 `general_api_access`
file: ./content/docs/developer/OAuth-API/api/v1/user/oauth/app/query-user-basic-info.mdx
meta: {
"title": "读取用户基本信息",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/user/oauth/app/query-user-basic-info",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "注:调用此API的最低权限为 `common`"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
注:调用此API的最低权限为 `common`
file: ./content/docs/developer/OAuth-API/api/v1/user/oauth/app/rotate-user-admin-token.mdx
meta: {
"title": "通过OAuth Token更新用户管理Token",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/user/oauth/app/rotate-user-admin-token",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "更新用户管理Token\n\n注:\n\n1. 调用此API的最低权限为 `trusted_full_access` ,您需要是一个已验证的开发者才有机会调用此接口\n2. 当且仅当返回200才可视为成功,必要时可对响应体的数据内容进行检查"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
更新用户管理Token
注:
1. 调用此API的最低权限为 `trusted_full_access` ,您需要是一个已验证的开发者才有机会调用此接口
2. 当且仅当返回200才可视为成功,必要时可对响应体的数据内容进行检查
file: ./content/docs/files-api/Files-API/api/v1/f/pr/fileuniqueid/p1.mdx
meta: {
"title": "文件下载接口(Private私有文件下载)",
"full": true,
"_openapi": {
"method": "GET",
"route": "/api/v1/f/pr/{fileUniqueId}/{p1}",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "# 简介\n\n通过此Get接口,可以在用于下载用户的所有文件\n\n调用此接口需要提供有效的APIKey凭证,如果启用了APIKey权限检查,需要具备 `file-v1` 的权限"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
# 简介
通过此Get接口,可以在用于下载用户的所有文件
调用此接口需要提供有效的APIKey凭证,如果启用了APIKey权限检查,需要具备 `file-v1` 的权限
file: ./content/docs/files-api/Files-API/api/v1/f/pub/fileuniqueid/p1.mdx
meta: {
"title": "文件下载接口(Public公开文件下载)",
"full": true,
"_openapi": {
"method": "GET",
"route": "/api/v1/f/pub/{fileUniqueId}/{p1}",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "# 简介\n\n通过此Get接口,可以在浏览器直接打开/下载对应的公开的文件\n\n镜像Host:\n`pi.dogenet.work`"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
# 简介
通过此Get接口,可以在浏览器直接打开/下载对应的公开的文件
镜像Host:
`pi.dogenet.work`
file: ./content/docs/other-api/Other-API/api/v1/openapi/search/google-search/v1.mdx
meta: {
"title": "Google Custom Search API",
"full": true,
"_openapi": {
"method": "GET",
"route": "/api/v1/openapi/search/google-search/v1",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "# Google Custom Search API\n\n为方便广大开发者将谷歌搜索能力接入到您的项目中,同时为了下一步的联网LLM服务推出做铺垫,现推出了谷歌官方搜索API转发服务。您现在可以直接在我们的站点调用接近原版的Google Custom Search JSON API。\n\n## 主要特性\n\n- **兼容性**:直接在本站调用官方Google Custom Search API,理论上可以直接兼容原有的支持Google搜索API的程序。\n- **成本效率**:默认提供查询结果的缓存功能,从而降低使用成本,提高查询效率。\n- **适用性**:为下一步的大语言模型的联网功能做铺垫。\n\n## 使用注意事项\n\n与官方原版API相比,存在以下区别:\n\n1. **`key` 参数(可选)**:\n - 该参数对应您在本站“设置”页面中获取到的APIKey。\n - 如果您直接以Bearer规范将您的Key放到请求头中,则此参数可以省略。\n\n2. **`cache` 参数(可选)**:\n - 为了降低使用成本,默认提供查询结果的缓存功能。\n - 默认情况下,认为相同查询条件下,3天内的缓存结果为有效。\n - 当命中缓存时,您的请求将不会被收取费用。\n - 参数可缺省,设置为0表示禁用缓存,最小值0,最大值30。\n\n3. **`cx` 参数(可选)**:\n - 默认此参数将会被设置为 `73d45d507c0b2430e`。\n - 可缺省,推荐缺省或填写为此值。\n - 不同的 `cx` 值也会影响缓存命中。\n\n除了以上这些,其它参数功能和用法完全一致(Tip:`q`参数就是查询参数了,必填,把关键词放进去就可以查了。)\n\nCurl示例\n\n```bash\ncurl --location --request GET 'https://api.ohmygpt.com/api/v1/openapi/search/google-search/v1?key=sk-xxx&q=Genshin&cache=1'\n```\n\n## 官方文档\n\n- Google官方开发文档:[Google Custom Search API](https://developers.google.com/custom-search/v1/using_rest)\n- Google官方参数说明文档:[API参数说明](https://developers.google.com/custom-search/v1/reference/rest/v1/cse/list)\n\n## 定价\n\n- 未命中缓存的成功的查询:**1500代币/次**\n- 命中缓存的查询:**免费**"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
# Google Custom Search API
为方便广大开发者将谷歌搜索能力接入到您的项目中,同时为了下一步的联网LLM服务推出做铺垫,现推出了谷歌官方搜索API转发服务。您现在可以直接在我们的站点调用接近原版的Google Custom Search JSON API。
## 主要特性
* **兼容性**:直接在本站调用官方Google Custom Search API,理论上可以直接兼容原有的支持Google搜索API的程序。
* **成本效率**:默认提供查询结果的缓存功能,从而降低使用成本,提高查询效率。
* **适用性**:为下一步的大语言模型的联网功能做铺垫。
## 使用注意事项
与官方原版API相比,存在以下区别:
1. **`key` 参数(可选)**:
* 该参数对应您在本站“设置”页面中获取到的APIKey。
* 如果您直接以Bearer规范将您的Key放到请求头中,则此参数可以省略。
2. **`cache` 参数(可选)**:
* 为了降低使用成本,默认提供查询结果的缓存功能。
* 默认情况下,认为相同查询条件下,3天内的缓存结果为有效。
* 当命中缓存时,您的请求将不会被收取费用。
* 参数可缺省,设置为0表示禁用缓存,最小值0,最大值30。
3. **`cx` 参数(可选)**:
* 默认此参数将会被设置为 `73d45d507c0b2430e`。
* 可缺省,推荐缺省或填写为此值。
* 不同的 `cx` 值也会影响缓存命中。
除了以上这些,其它参数功能和用法完全一致(Tip:`q`参数就是查询参数了,必填,把关键词放进去就可以查了。)
Curl示例
```bash
curl --location --request GET 'https://api.ohmygpt.com/api/v1/openapi/search/google-search/v1?key=sk-xxx&q=Genshin&cache=1'
```
## 官方文档
* Google官方开发文档:[Google Custom Search API](https://developers.google.com/custom-search/v1/using_rest)
* Google官方参数说明文档:[API参数说明](https://developers.google.com/custom-search/v1/reference/rest/v1/cse/list)
## 定价
* 未命中缓存的成功的查询:**1500代币/次**
* 命中缓存的查询:**免费**
file: ./content/docs/other-api/Other-API/api/v1/openapi/search/serper/v1.mdx
meta: {
"title": "Google Search By Serper",
"full": true,
"_openapi": {
"method": "POST",
"route": "/api/v1/openapi/search/serper/v1",
"toc": [],
"structuredData": {
"headings": [],
"contents": [
{
"content": "## 简介\n\n仍然是谷歌搜索,但是由第三方提供,费用更低,调用简单,效果更好,网站的内嵌LLM搜索服务就是基于实现的。\n\n## 定价\n\n- 未命中缓存的成功的查询:**500代币/次**\n- 命中缓存的查询:**免费**\n"
}
]
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}
## 简介
仍然是谷歌搜索,但是由第三方提供,费用更低,调用简单,效果更好,网站的内嵌LLM搜索服务就是基于实现的。
## 定价
* 未命中缓存的成功的查询:**500代币/次**
* 命中缓存的查询:**免费**
file: ./content/docs/files-api/Files-API/api/v1/f/pub/metadata/fileuniqueid/p1.mdx
meta: {
"title": "公开文件元数据获取",
"full": true,
"_openapi": {
"method": "GET",
"route": "/api/v1/f/pub/metadata/{fileUniqueId}/{p1}",
"toc": [],
"structuredData": {
"headings": [],
"contents": []
}
}
}
{/* This file was generated by Fumadocs. Do not edit this file directly. Any changes should be made by running the generation command again. */}